Git学习笔记 #3 远程仓库使用
本文最后更新于:2022年5月19日 中午
接上文,本文介绍了 Git 在远程仓库的使用,以及合作开发的简易教程。
本文大部分内容参考了 RCY 同学的教程,部分参考了 廖雪峰教程-Git,菜鸟教程-Git,以及 Git 官网文档 Git-Documentation。
远程的 Git
尽管 Git 本身是分布式的,但我们通常需要一个服务器来同步、传递我们的本地仓库数据,处于一种「伪集中式」的状态。但服务器上的内容不一定是最新的内容,只是一个用于传递的中间态而已。
因此有了一系列的相关网站,通常来说我们用以下两个:
- GitHub:⼀个基于 Git 的代码托管服务平台,开源社区交流代码的重要网站,参考 https://www.github.com/ 。
- GitLab:类似 Git,有完善的管理界面和权限控制,一般用于在企业、学校等内部网络搭建 Git 私服,参考 https://www.gitlab.com/ 。
从代码的私有性上来看,GitLab 是一个更好的选择。但是对于开源项目而言,GitHub 依然是代码托管的首选。
鉴权
在使用远程仓库之前,我们要先解决鉴权问题:云服务器需要知道你是否有权力访问这个仓库。
鉴权有两种方法:
- 用户名 + 密码
- SSH 密钥对
通常来说,使用密钥对比用户名密码更安全,这里不介绍相关原理,先简单讲下密钥对的配置。
1 | |
密钥对生成时会需要设置密码,但由于其本身就是加密的,密码只是为了适应更特殊的情景,这里可以直接回车跳过。
cat 命令会把公钥放到标准输出,复制到 GitHub 或 GitLab 上的对应位置即可。注意 id_rsa.pub 是可以公开的,而私钥存储在 id_rsa 文件,用于在每次操作远程仓库时与公钥进行匹配。
如果你有多台电脑或服务器,可以分别在各个主机上生成各自的 SSH 密钥对,并将公钥复制到 GitHub 或 GitLab,并区分命名。这样就可以实现在不同主机上的鉴权,方便多地办公。
克隆远程仓库
远程仓库通常是由 clone 或 push 开始的,这里假设我们已经在 GitHub 上有了一个仓库,现在要将其克隆到本地。
常见的克隆方法有两种:
1 | |
前者不需要配置 SSH 也能完成,但是每次操作远程仓库都需要用户名和密码。后者是在配置完 SSH Key 后使用的,可以省去填写用户名和密码的步骤,也能帮助你克隆私有仓库。如果前面生成密钥对时设置了密码,这里就需要输入。
此外,如果要克隆一个较大的仓库(仓库有很长的提交历史或大量二进制文件),常用的一个方法是限制 clone 的深度,只克隆最新的版本:
1 | |
远程分支
现在对本地仓库查看 log,会发现除了 HEAD、main 这些原有的指针,还多了 origin/ 的字样,这是远程仓库分支的默认标识。
这些远程分支与本地分支并存,反映了远程仓库在你上次和它「通信」时的状态,可以用前面的命令查看:
1 | |
同样,也可以用 git checkout 切换到任意一个远程分支,只需要加上 origin/。
远程分支有一个特别的属性,在你检出时自动进入一个「分离 HEAD 状态」。在此状态下,不会有
HEAD -> origin/main -> node,而是直接有HEAD -> node。这样做是因为 Git 不能直接在远程分支上进行操作,必须在本地操作后将 main 分支同步到远程,origin/main 才会发生变动。一旦发生了分离 HEAD 并提交修改,下次 push 时本地仓库将与远程仓库发生分歧,可能需要 Rebase 操作。
在实际操作中,我们只需要检出到本地分支即可。当克隆一个仓库时,它通常会自动地创建一个跟踪 origin/main 的 main 分支。
但如果一个远程分支 origin/test 在本地没有对应分支 test,我们却要检出 test,该命令会自动复制一个「跟踪分支」作为本地分支。
本地与远程的交互
下载 (Fetch)
所谓的拉取通常可由两个操作来完成,初学者往往分不清两个操作究竟分别做了什么:
1 | |
下面我们用一组图来解释 git fetch 操作:
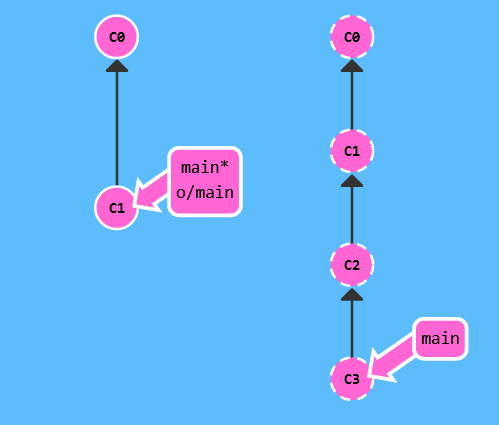
在这个例子中,虚线的结点代表远程仓库,它有两个我们本地仓库中没有的提交。而此时本地的远程分支 origin/main 还停留在你上次和它「通信」时的状态。如果此时使用 git fetch,则会出现:
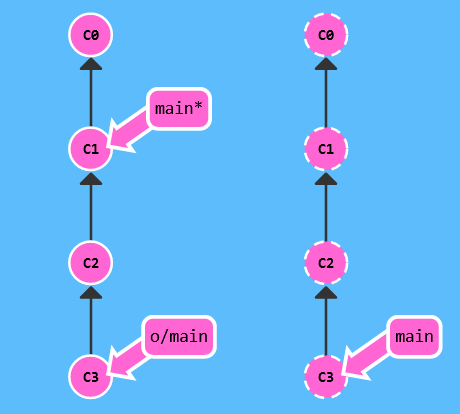
可以发现,本地仓库缺失的结点 C2 和 C3 被下载到了本地仓库,同时远程分支 origin/main 也被更新,反映到了这一下载,但是本地分支 main 依旧不变!
因此,我们可以知道:git fetch 并不会改变本地仓库的状态。它不会更新你的 main 分支,也不会修改你磁盘上原有的文件使其与远程「同步」,它只是将「同步」这一操作所需要的数据都下载下来了。
拉取 (Pull)
那么,如何将这些数据真正完成「同步」呢?实际上有很多方法,上一节提到的 git merge origin/main 和 git rebase origin/main 等命令都可实现。
实际上,由于先抓取更新再合并到本地分支这个流程很常用,因此 Git 提供了一个专门的命令来完成这两个操作。它就是我们要讲的 git pull。
这里我们先用一个分叉的例子来演示:
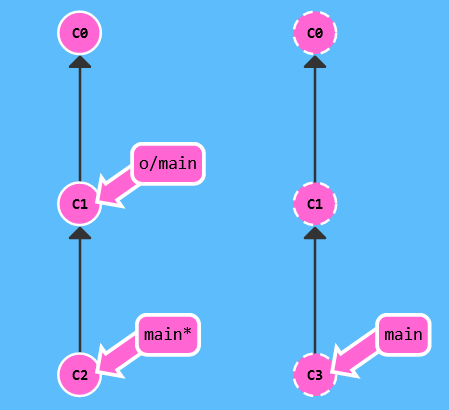
分叉 (Branch Diverged) 是由于不同开发者进行了时空错位的提交导致的。观察该图,我们可以猜测本地开发者是在 C1 时刻克隆的仓库,并再克隆后完成了一次 C2 提交,而与此同时,另一个开发者在远程完成了 C3 提交。
此时如果想提交代码到远程,会提示 main 分支发生了分歧——因为远程仓库包含了本地尚不存在的结点,无法通过快速前移直接合并。Git 会提示你先将远程仓库拉取到本地解决分叉。
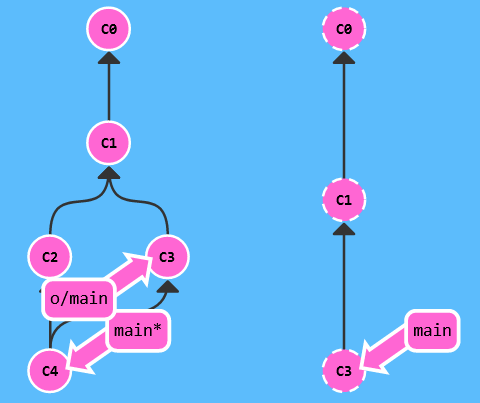
可以看到,git pull 其实就是 git fetch 和 git merge origin/main 两个指令的缩写。
需要注意的是,如果此时 C2 和 C3 有冲突,则 git pull 不完全执行,需要手动维护后再 merge,这个维护的过程对另一开发者是不可见的。
在实际操作中,我们偶尔会用
git fetch和git rebase origin/main来避免一个不必要的合并。
推送 (Push)
相比于拉取,推送操作就尤为简单:
1 | |
如果无分歧发生,远程仓库将会接收本地新增的结点,而远程仓库中的 main 也会指向本地仓库中 main 的位置。此外,本地仓库的远程分支 origin/main,会在这次「通信」的过程中,也移动到本地 main 的位置。
再回顾一下上面的分叉的例子,如果我们已经 merge 解决了冲突,这时再用 git push 则会有:
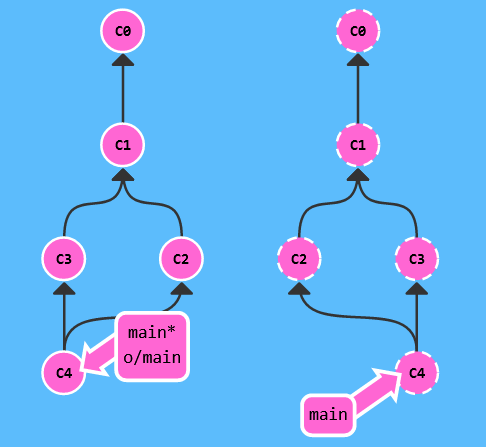
可以看到,远程仓库清楚地记录了这次 merge 的历程!
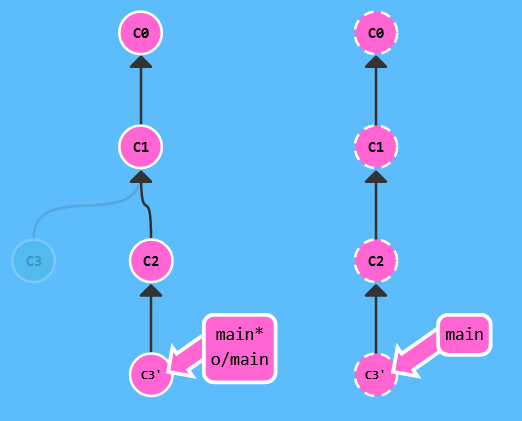
而如果我们用 git fetch 和 git rebase origin/main 的组合(虽然很繁琐),但是远程仓库历史将变得十分整洁,并且能清楚地体现提交顺序。
Push 的参数
上文介绍了最简单的 Push 命令,但这个命令看似简单,实际上却是最「模糊」的,很容易出现报错。完整的 Push 指令应该是:
1 | |
这个命令显式地指出了远程仓库名,如果只关联了一个远程,这个参数就可以缺省。但是如果关联了多个仓库(如 GitHub 和 Gitee),则必须用这个参数指明。使用 git remote -v 命令可以查看关联的远程仓库。
此外,它还指出了本地分支及其映射的上游分支,该命令可以用于不同名分支的推送,但实际工程中我们倾向于用本地远程同名分支(避免分歧),因此命令可以简化为:
1 | |
但是,如果远程仓库 origin 没有一个同名的 test 分支,又会报错,此时我们需要为 test 建立上游分支,并将其跟踪绑定:
1 | |
注意,一次 Push 默认只推送一个分支,因此如果不加分支名,会默认推送当前 HEAD 所在的分支。因此指令还可以逐步缺省:
1 | |
最后一条指令就是我们最早提及的推送命令,它需要满足:
- 只有一个远程仓库;或者有多个仓库,但用
-u绑定其中一个。 - 只有一条分支;或者有多条分支,但当前分支与上游分支同名并绑定。