IR课程项目-文学检索-开发文档
本文最后更新于:2022年5月19日 中午
![]()
Date:2021-08
Description:本文档作为 2021 年夏季学期 IR 课程 Project 搜索引擎搭建的开发文档,检索主题为「文学」。
Reference:参考自 CHH12 的 实现方案,在其基础上改进了算法,适配了现版本工具并完善文档。
Copyleft:© 2021 Hwcoder. Some rights reserved.
系统说明
中国文学有数千年悠久历史,以特殊的内容、形式和风格构成了自己的特色,有自己的审美理想,有自己的起支配作用的思想文化传统和理论批判体系,是世界文学宝库中光彩夺目的瑰宝。
本搜索引擎主要收录了与中国文学有关的网页文档,包括但不限于民族文学、宗教文学、语言文学、诗词文学、中国外国文学等,爬取网站均来自中国社科院等官方机构。
系统架构
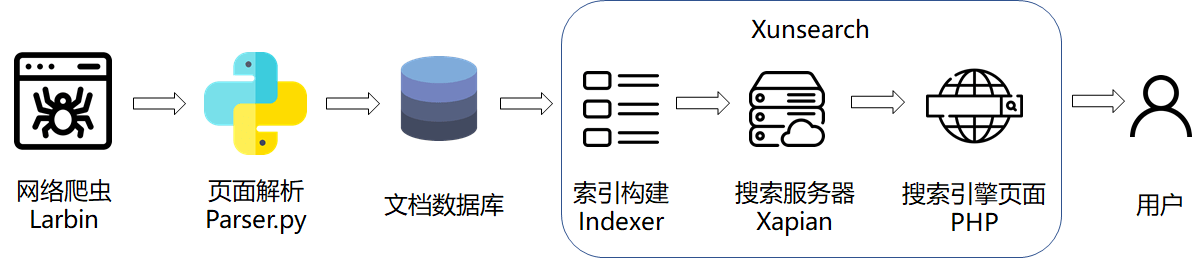
本搜索引擎系统主要架构如上图所示。
检索的源文档由网络爬虫从给定的种子页面开始爬取,爬取到本地后利用 Python 中的 BeautifulSoup4 模块进行网页的解析,并写入文档数据库中。 之后利用搜索引擎解决方案 Xunsearch(迅搜)构建搜索引擎,利用索引器 Indexer 对文档数据进行索引,并构建基于 Xapian 的后端搜索服务器与前端的搜索应用,向用户展示出搜索功能。
模块介绍
网络爬虫:Larbin
Larbin 是一种开源的网络爬虫,用 C++ 语言实现。其设计简单,具有高度的可配置性,能够配置抓取深度、间隔、并发度、代理,并支持通过后缀名对抓取网页进行过滤。Larbin 具有非常高的效率,可以轻易获取单个网站的所有链接,自动扩展 url 页面并抓取与保存,从而为搜索引擎提供广泛的数据来源。
然而,Larbin 只是一个爬虫,只抓取网页,并不负责网页的解析、数据库的存储以及索引的建立,也不支持分布式系统。另外,Larbin 已经较长时间不再更新,因而不支持 https 协议,这在今天很大程度上造成了网页页面的局限性。
这里采用由国人在基于原版 Larbin2.6.3 版本上继续开发并发布于 GitHub 的 Larbin2.6.5 版本进行搜索引擎系统的构建。
项目网址:https://github.com/ictxiangxin/larbin
网页解析:BeautifulSoup4 (bs4)
BeautifulSoup4 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库。
由于 HTML 和 XML 文件本身是结构化的文本,有一定的规则,通过它的结构可以简化信息提取。类似的网页信息提取库还有 Lxml 和 Pyquery 等,但是 bs4 相比其他的库更加简单易用。
本项目就采用 BeautifulSoup4 快速对网页文档内容进行解析和格式化。
官方文档:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
前端&搜索引擎:Xunsearch & Xapian
Xunsearch(迅搜)是一款以 GPL 协议开源发布的高性能、全功能的全文检索解决方案,并针对中文深度优化和处理,用于帮助开发者针对海量数据快速建立搜索引擎。
Xunsearch 采用结构化分层设计,包含后端服务器和前端开发包两大部分。后端是用 C/C++ 基于 Xapian 搜索库、SCWS 中文分词、libevent 等开源库开发,借鉴了 nginx 的多进程多线程混合工作方式,是一个可承载高并发的高性能服务端。前端则是使用流行的脚本语言编写了开发工具包(SDK)。
本项目采用 Xunsearch 还考虑了以下特点:
- 具有为搜索而自主开发 SCWS 中文分词库,支持复合分词、自定义补充词库,保障查全率、准确率。
- 索引接口齐全,索引添加简便,支持实时搜索,支持多种数据源(SQL、JSON、CSV 等)。
- 除通用搜索引擎功能外,还内置支持拼音检索、分面搜索、相关搜索、同义词搜索、搜索纠错建议等专业功能。
官方地址:http://www.xunsearch.com/
此外,Xunsearch 的高速响应能力还离不开 Xapian 这一搜索引擎库。
Xapian 是一个允许开发人员轻易地添加高级索引和搜索功能到他们的应用系统的高度可修改的工具,它在支持概率论检索模型的同时也支持布尔型操作查询集。
Xapian 相比 Lucene 有更多的优势:基于 C++ 开发的强可移植性(可以运行在 Linux, MacOS, Windows 系统上),丰富的查询机制(概率性搜索排名、相关度反馈、邻近搜索、布尔搜索、词干提取、通配符查询、别名查询、拼写纠正等)和较强的检索性能。
设计文档
运行环境
主机:
- 系统:Windows 10
- 带宽:40 Mbps
虚拟机:
- 软件:Oracle VM VirtualBox 6.1.26
- 配置设置:
- 内存:2GB
- 磁盘:20GB
- 处理器:Intel(R) Core(TM) i5-9300H CPU @ 2.40GHz(核心数:1)
- 系统:Linux Ubuntu 20.04
- 依赖环境:
- Apache 2.4.41
- PHP 7.4.3
- Python 3.8.10
总体设计流程
- 安装 Ubuntu 虚拟机,配置环境,安装 Larbin 和 Xunsearch。
- 配置 Larbin 爬虫选项,选定种子页面,爬取文档。
- 利用 BeautifulSoup4 模块编写脚本 Parser.py 解析文档,存储为 csv 文件。
- 生成 Xunsearch 配置文件,构建索引,生成搜索框架。
- 部署至 Apache HTTP Server,前后端代码再开发,优化搜索页面。
各模块设计细节
网络爬虫
网络爬虫模块使用 Larbin2.6.5 进行网页文档的爬取。在按照配置进行爬取 30 分钟后,最终获得 10965 个文档(约 409 MB)。由于爬虫自身的限制,这些文档均来自 http 站点。
以下是关键的配置项及说明:
- 是否锁定种子站点:否。取消锁定才能根据链接爬取到更多内容。
- 是否使用扩展链接:否。大部分网页为了提高排名,都会引入无关的友链,由于本项目是专题检索,故关闭此功能避免进入其他域名。
- 同一个服务器的两次请求的间隔时间:无限制。通常基于礼貌原则,我们应该限制访问频率,但由于关闭了扩展链接,爬虫只会在少数域名中爬取,如果限制了间隔时间会使得爬取效率极低。
- 是否哈希页面以去重:是。由于站点固定,去重可以减少大量数据冗余。
以下是种子网页地址:
- http://philosophychina.cssn.cn/ (中国哲学网-中国社科网子域名)
- http://literature.cssn.cn/ (中国文学网-中国社科网子域名)
- http://cel.cssn.cn/#story1 (中国民族文学网-中国社科网子域名)
- http://ling.cssn.cn/ (中国语言文学网-中国社科网子域名)
- http://iwr.cssn.cn/ (中国宗教文学网-中国社科网子域名)
- http://ifl.cssn.cn (中国外国文学网-中国社科网子域名)
- http://www.china-language.edu.cn/ (中国语言学网)
- http://www.huaxiawen.com/ (华夏古代文学网)
- http://www.zgwenxue.com/ (中国文学网)
- http://www.eduwx.com/ (教育文学网)
- http://www.wgwxzz.cn/ (外国文学网)
- http://www.zhexue.org/ (哲学网)
- http://www.52shici.cn/ (吾爱诗词网)
在终端运行爬虫过程如下:
打开 localhost:8081 查看统计结果:
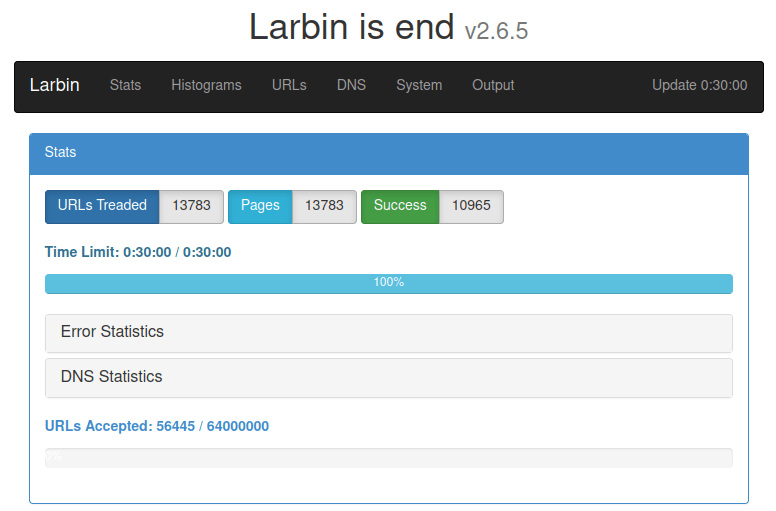
从统计结果可以看出,共收到 13783 个 URL,访问了 13783 个页面,最终成功爬取 10965 个页面。
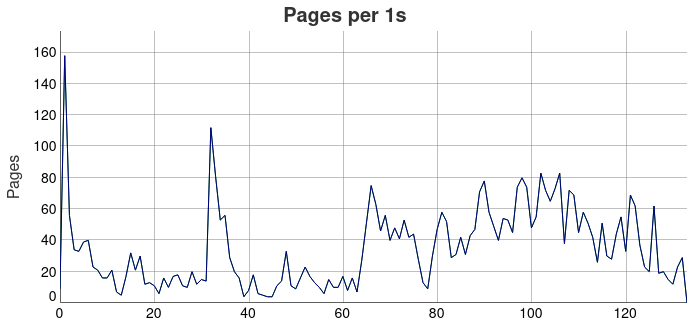
从上图可以具体地得出爬虫的爬取效率,可见爬虫爬取的速度随着时间的推移会发生较大的变化。
网页解析
解析器模块利用 Python 的 BeautifulSoup4 和 Pandas 模块编写,前者可以对网页文档进行解析,后者便于将数据以 csv 文件形式保存,便于后续搜索引擎使用。
调用 BeautifulSoup4 的代码如下:
1 | |
调用 Pandas 的代码如下:
1 | |
处理结果如下:

可以看到每个文档被分出 id, title, body, urls 四个字段,存储在一个 csv 文件中。
前端&搜索引擎
搜索引擎模块利用 Xunsearch 提供的开发工具即可实现。首先确定运行环境正常,然后编写配置文件对格式化的 csv 文件建立索引,并生成搜索骨架代码,即可实现基本检索功能。
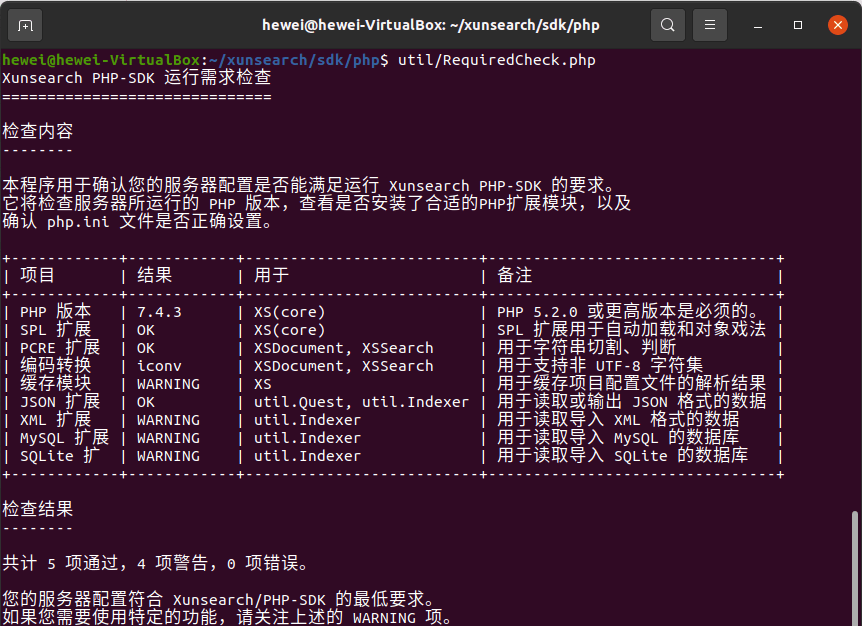
首先利用工具包中的 RequiredCheck 检查当前环境是否满足 Xunsearch 的运行条件:
环境正常后,利用工具包中的配置文件生成工具 IniWizzard,在 Web 交互页面中即可完成各个字段的设计:
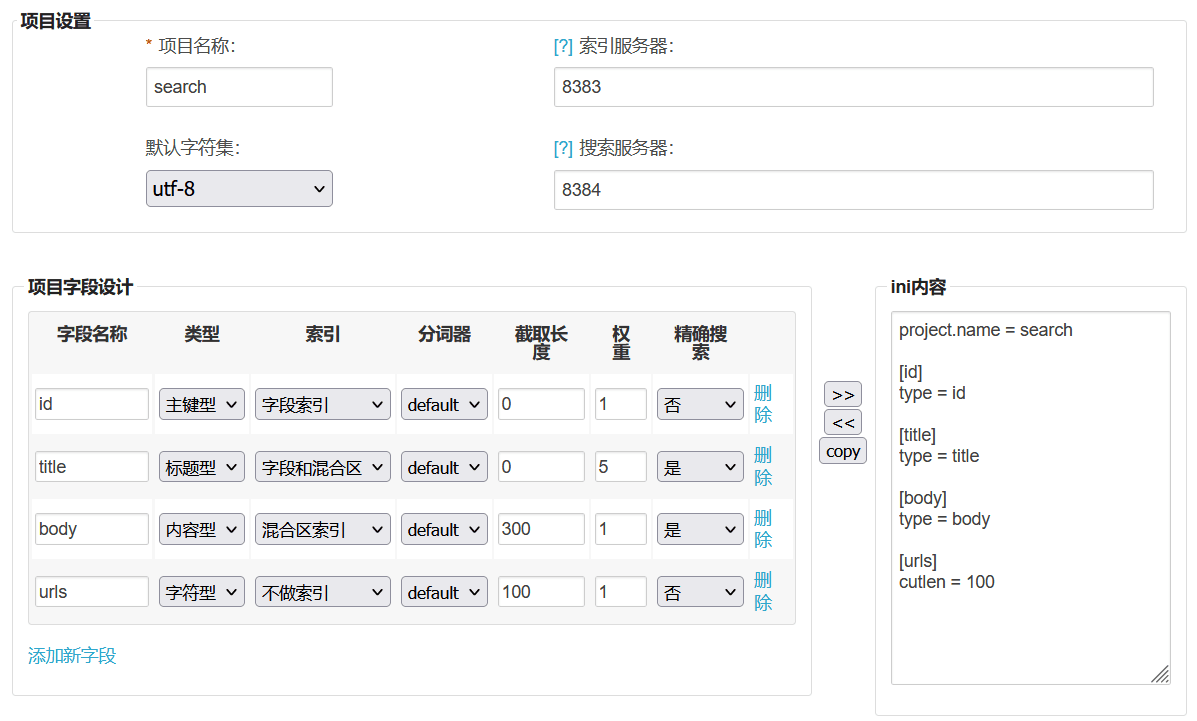
其中,各个字段的含义如下:
- id 为主键,作为每个文档的标识符。
- title 为文档的标题,赋予较高权重。
- body 为文档的内容,截取 300 个字符作为搜索结果的摘要显示。
- urls 作为每个文档在展示时的附属信息,不需要进行索引。
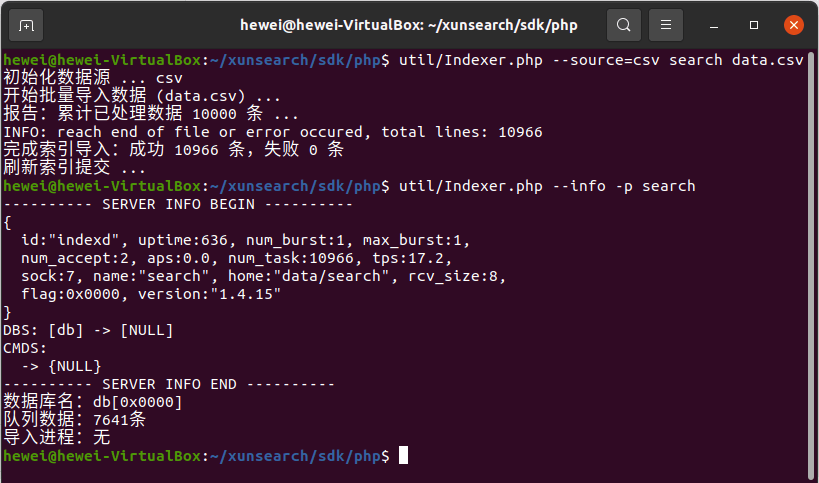
此后,就可以用工具包中的索引管理器 Indexer 批量建立索引:
在 db 文件夹下,可以看到建立的索引文件:
此时,可以用工具包中配备的测试工具 Quest,在当前索引中进行测试搜索,测试给定查询词的返回的数据。
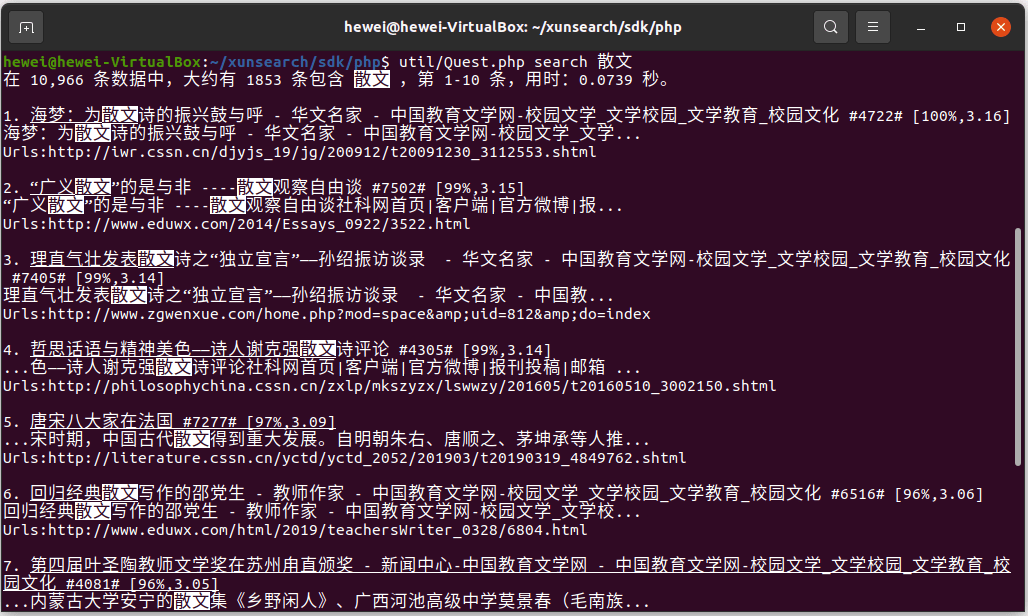
可以看到搜索功能已经可以使用了,这时需要用到工具包中的骨架代码生成工具 SearchSkel,生成前端代码。
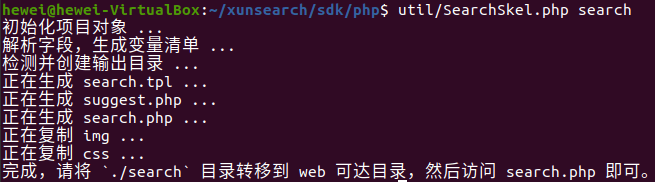
最后,运行 Apache2.0,将生成的 search 目录放到 /var/www/html 中,即可在本地服务器 localhost 访问搜索页面,实现搜索引擎的功能。
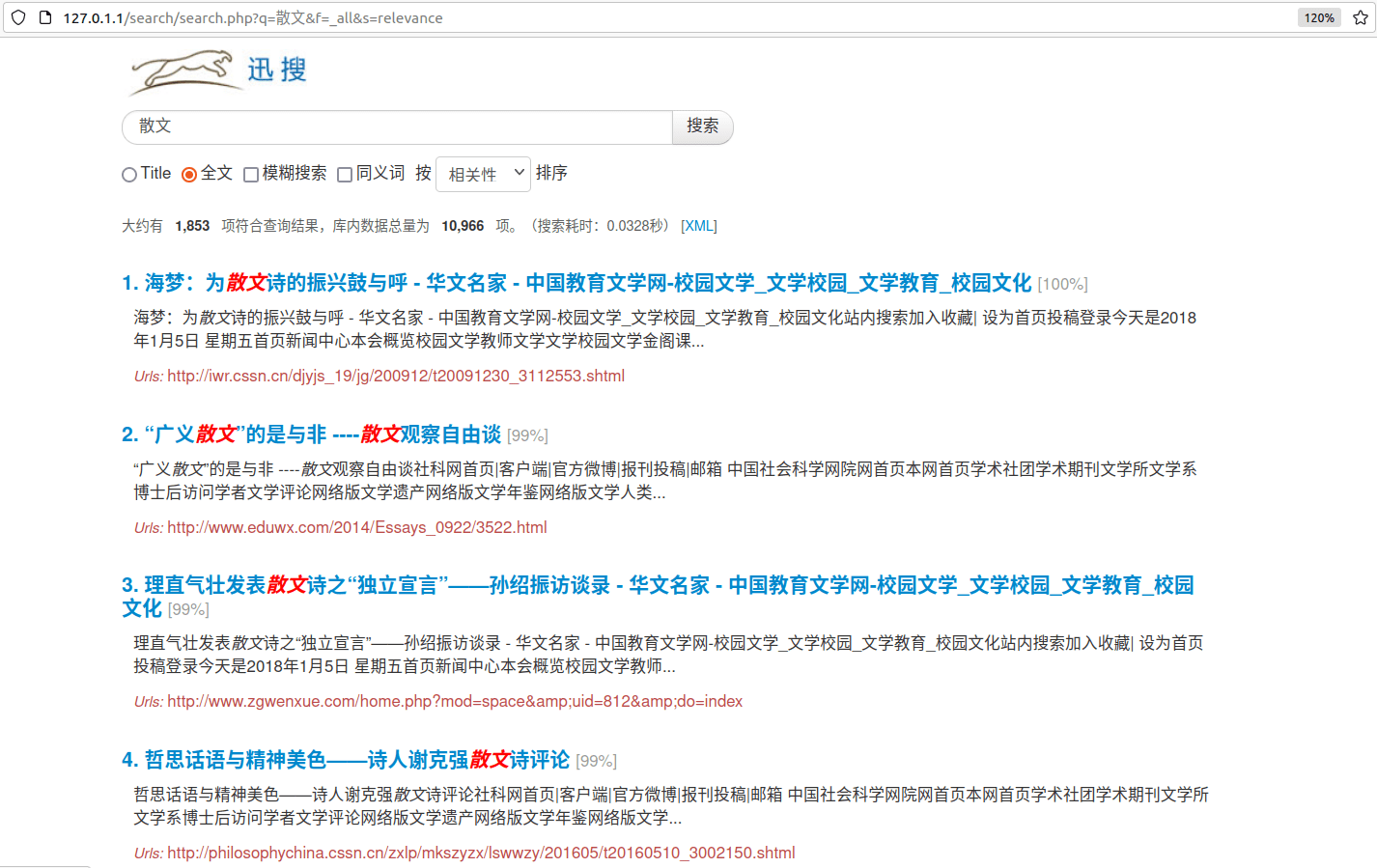
点击文档标题,会返回对应的文档主键(id):
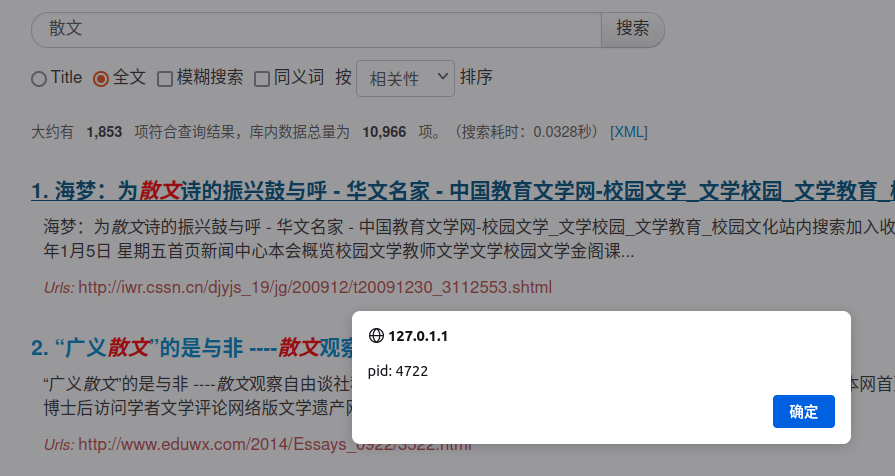
页面再开发
可以看到,直接生成的框架文件有如下的不足:
- 前端较为简陋,重点不够突出。
- 由于使用了国外的 cdn,访问速度较慢。
- 搜索结果点击后无法直接跳转至页面。
开发 style.css 和 search.tpl 文件后,可以得到新的页面:
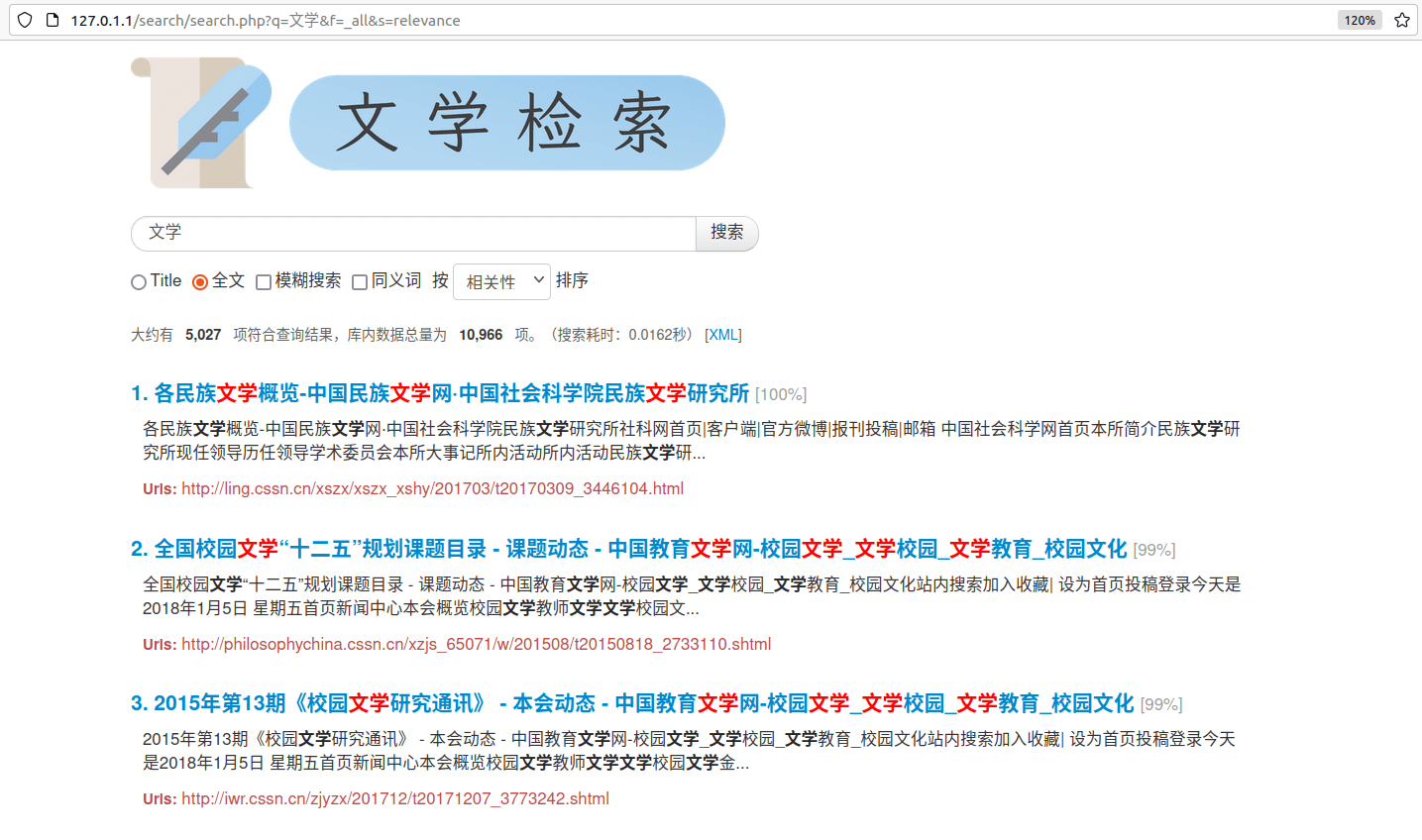
页面展示
网站部署到 web 可访问目录后,可以通过虚拟机的端口转发设置,实现在主机上访问,也可以购买 HTTP 映射服务后在给定域名访问。这里选择最简单的在虚拟机中访问。
首页
使用搜索前:

使用搜索后:
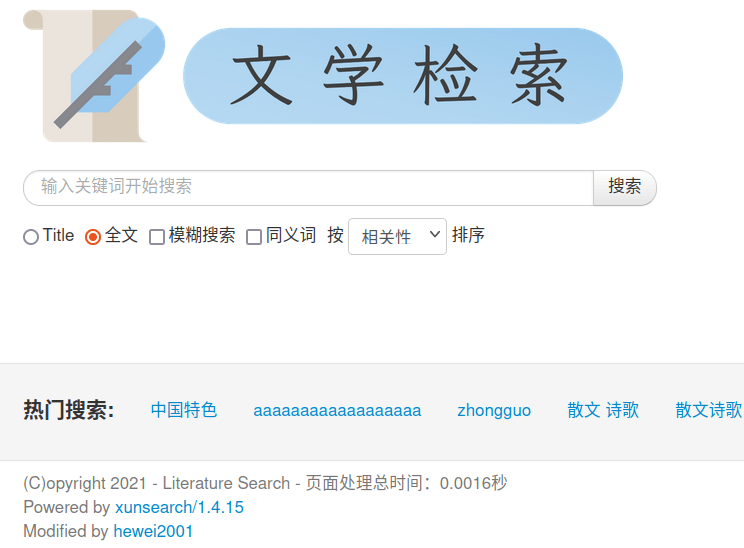
在使用了搜索功能后,搜索引擎将分析搜索日志,从而提供热门搜索词。 此外,可以看到搜索时可以选择多种方式,页脚有标明版权、处理时间以及作者的信息。
搜索页面
点击搜索后,会反馈查询结果的标题、文档摘要以及文档对应的原网址,并进行对查询词进行高亮表示(标题中红字、摘要中加粗),并会返回检索条目、检索时间、检索相似度等信息。
特别地,在页脚还提供了相关的搜索内容的联想,下图是在搜索「散文」后的联想:
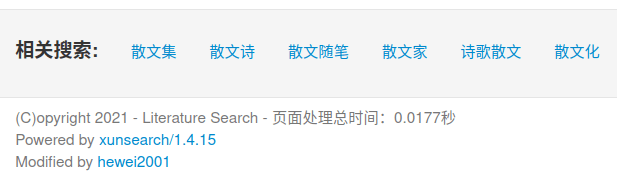
部分功能
- 查询联想
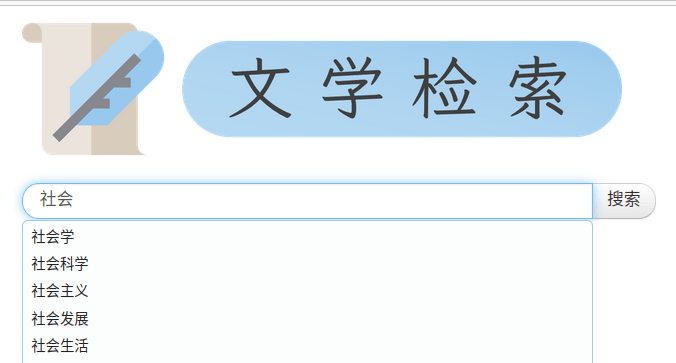
- 拼音联想
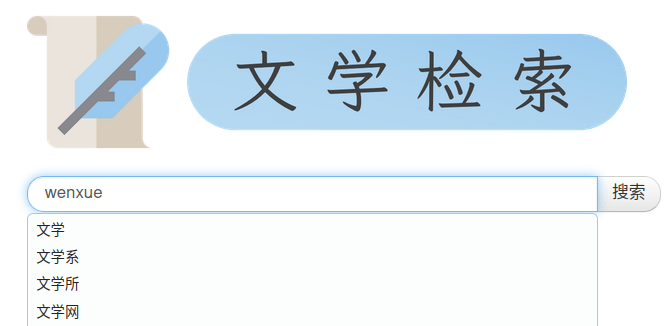
- 搜索纠错
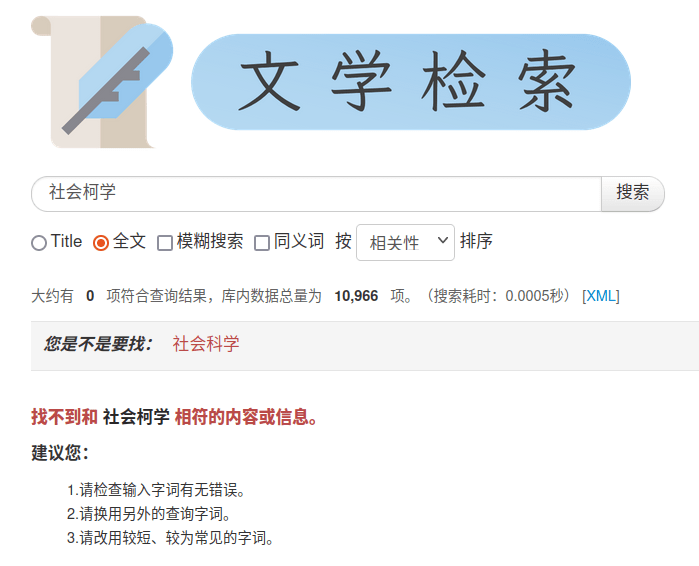
- 拼音纠错

- 布尔检索
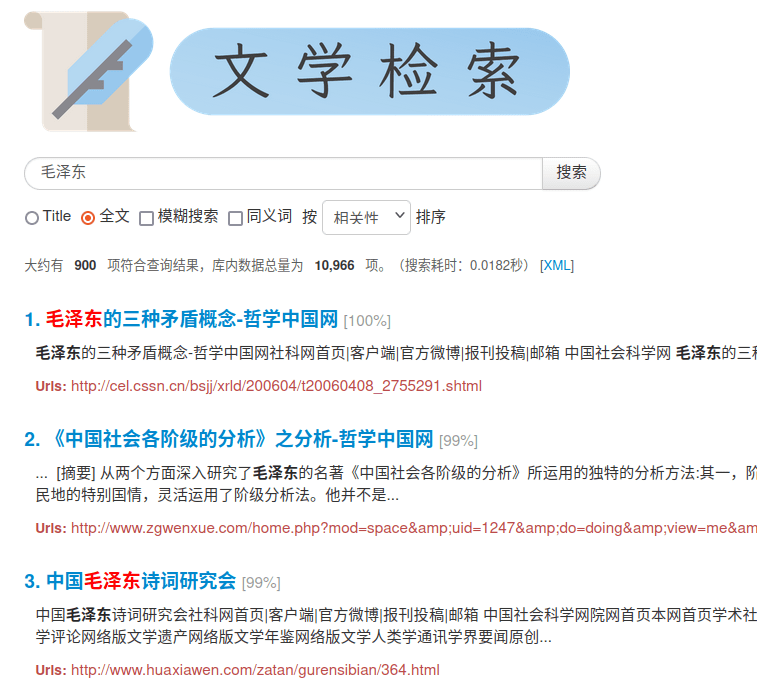
插入否定连接词后:

性能评估
下表随机选取 10 个与本搜索引擎相关的查询词进行检索,评估搜索引擎的 Top5 查准率(precision@5)与平均响应时间(mean responding time)。
| 查询 | 查准率@5 | 响应时间/s | 匹配文档总数 |
|---|---|---|---|
| 校园文学 | 4 | 0.0219 | 2000 |
| 宗教文学 | 5 | 0.0186 | 1000 |
| 汉语 | 5 | 0.0210 | 990 |
| 藏语 | 3 | 0.0229 | 68 |
| 季羡林 | 1 | 0.0173 | 50 |
| 鲁迅 | 4 | 0.0188 | 501 |
| 毛泽东诗词 | 5 | 0.0221 | 300 |
| 马克思主义哲学中国化 | 5 | 0.0356 | 100 |
| 散文作品 | 4 | 0.0128 | 800 |
| 小说集 | 3 | 0.0225 | 120 |
计算得:平均查准率为 3.9,平均响应时间为 0.02135s。
从结果上看,该搜索引擎在对应领域有着良好的表现,且响应迅速,但是对著名人物作品的查询则稍显不足。
此外,在部分检索结果中,有些无关文档由于重复出现了查询词而被赋予较高的「相似度」,但实际上 Top 10 返回结果的「相似度」都很高,可以考虑用 PageRank 等算法优化网站排名,提高 MRR 等指标。