手撕经典算法 #3 Transformer篇
本文最后更新于:2025年3月18日 下午
本文在前两章的基础上,对 Transformer 模型进行了简单的实现和注释。包括:
- Embedding 层
- Encoder 层
- Decoder 层
- 堆叠 Encoder
- 堆叠 Decoder
- 完整 Transformer
Embedding 层
Transformer 模型的基础组件之一是嵌入层。Token Embedding 将输入的单词或标记转换为向量表示,Positional Embedding 则为输入的每个位置添加位置信息,以便模型理解序列的顺序。
Token Embedding
以下是 Token Embedding 的代码实现:
1 | |
Position Embedding
在 Transformer 模型中,位置编码被添加到输入的嵌入表示中。位置编码的计算通常基于固定函数,例如正弦和余弦函数。这些函数确保不同位置的编码是不同的,同时保持一定的周期性和对称性。
具体地,位置编码矩阵 \(\mathbf{PE}\) 的每个元素由以下公式计算:
\[ \mathbf{PE}_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right) \] \[ \mathbf{PE}_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right) \]
其中: - \(pos\) 表示位置索引。 - \(i\) 表示维度索引。 - \(d_{\text{model}}\) 表示嵌入维度的大小。
这些公式确保了不同位置的编码是独特的,并且具有不同频率的正弦和余弦成分。以下是 Positional Embedding 的代码实现:
1 | |
RoPE Embedding
TODO
Encoder 层
Transformer 的 Encoder 由多个子层组成,包括多头注意力机制(Multi-Head Attention)、前馈神经网络(Feed Forward Neural Network)以及归一化层(Layer Normalization)。
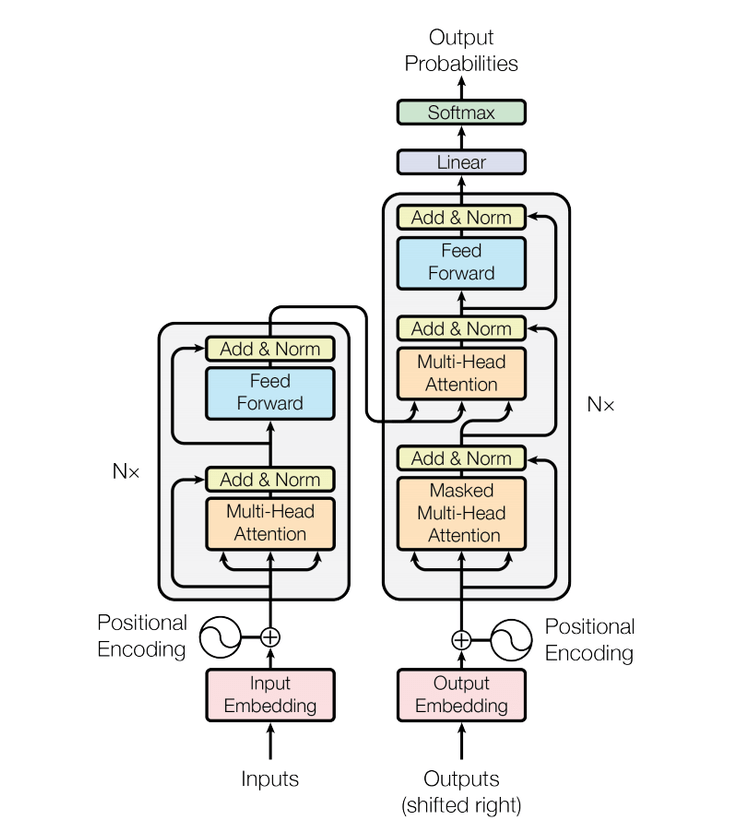
代码实现如下:
1 | |
Decoder 层
Transformer 的 Decoder 层和 Encoder 层有类似的结构,但 Decoder 层除了包含多头自注意力机制和前馈神经网络,还增加了一个用于编码器-解码器注意力机制的多头注意力子层。这使得 Decoder 层能够同时关注当前输出序列的上下文信息和输入序列的编码信息。多个 Decoder 层堆叠在一起构成整个 Decoder 模块。
代码实现如下:
1 | |
堆叠 Encoder
多个 Encoder 层堆叠在一起构成整个 Encoder 模块。
代码实现如下:
1 | |
堆叠 Decoder
1 | |
Transformer
Transformer 由三个主要部分组成:输入嵌入(Token Embedding 和 Positional Embedding)、Encoder 堆叠、Decoder 堆叠。下面将这些部分组合在一起,实现一个完整的 Transformer 类。
1 | |