OpenAI o1 系列模型背后的技术猜测
本文最后更新于:2024年12月14日 晚上
首先是两篇官方博客原文:
OpenAI o1 背后的技术
结合以下几个现象,来猜测一下 OpenAI o1 背后的秘密:
第一,是两个月前发布的 CriticGPT,探索了 Text Critic 作为反馈或奖励,会优于 Numerical Value 作为奖励的效果。P.S. Google 前不久也发了一篇 GenRM,看来也在往这个方向上靠。
第二,是模型的推理速度和价格,官方博客中的一个演示中,GPT-4o 用时 3s,o1-mini 用时 9s,o1-preview 用时 15s。而在官网的价格表中,我汇总了下表。如果认为 4o 和 o1 的规模相近,4o-mini 和 o1-mini 的规模相近,那么增加的时间和成本只可能是 Test-time Compute 带来的。
| 模型 | 输入价格 | 输出价格 |
|---|---|---|
| gpt-4o-2024-08-06 | $2.50 / 1M input tokens | $10.00 / 1M output tokens |
| gpt-4o-mini-2024-07-18 | $0.150 / 1M input tokens | $0.600 / 1M output tokens |
| o1-preview-2024-09-12 | $15.00 / 1M input tokens | $60.00 / 1M output tokens |
| o1-mini-2024-09-12 | $3.00 / 1M input tokens | $12.00 / 1M output tokens |
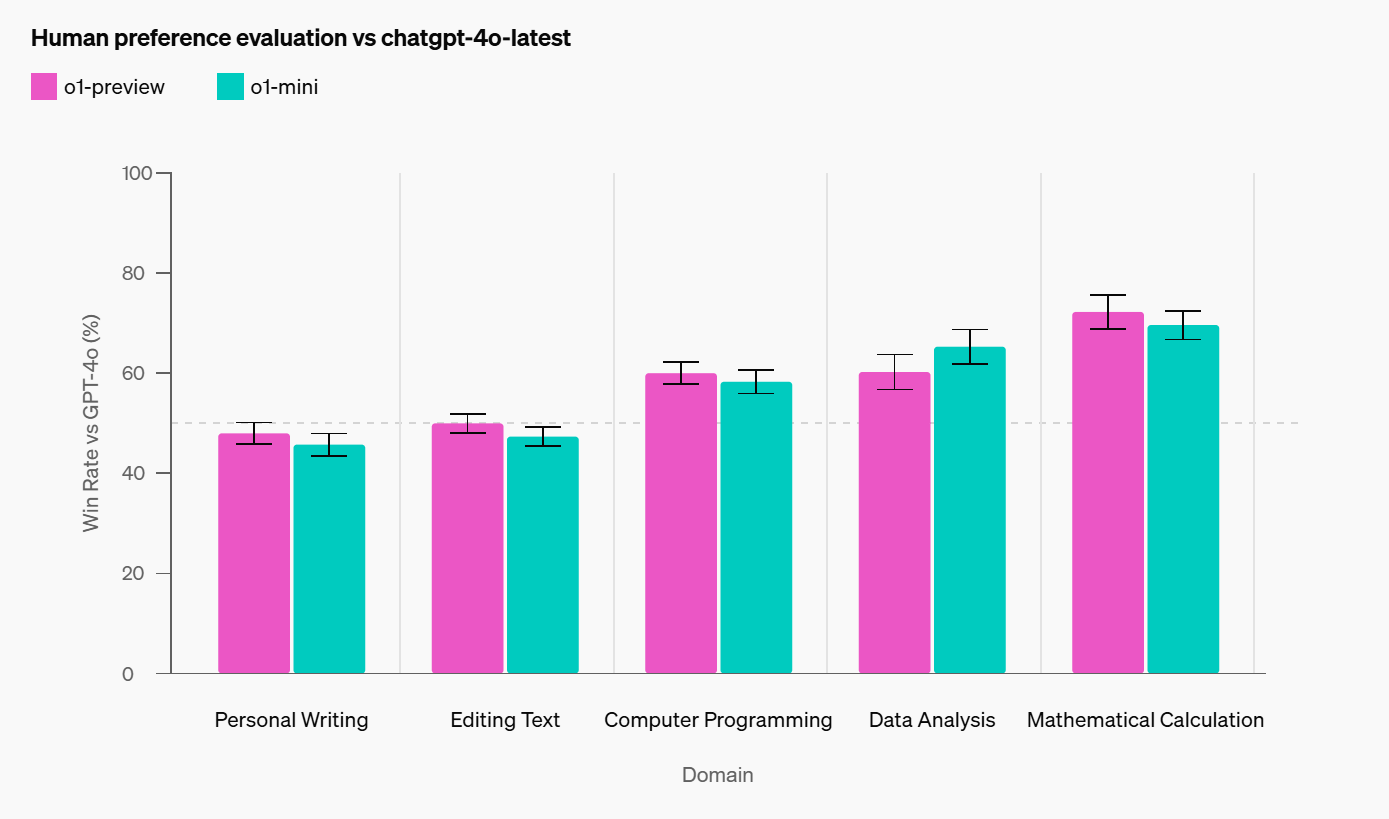
第三,是模型表现,博客中提到 o1 在推理密集的复杂任务上取得了增益,但在文本相关的简单任务没有太多区别。这也印证了第一点,这种 Critic 训练策略可能只适合于推理任务,文本任务可能区分度没有那么大(分不出好坏,不好给奖励),导致没优势。
Similar to o1-preview, o1-mini is preferred to GPT-4o in reasoning-heavy domains, but is not preferred to GPT-4o in language-focused domains.
与 o1-preview 类似,o1-mini 在偏重推理的领域优于 GPT-4o,但在偏重语言的领域则不优于 GPT-4o。
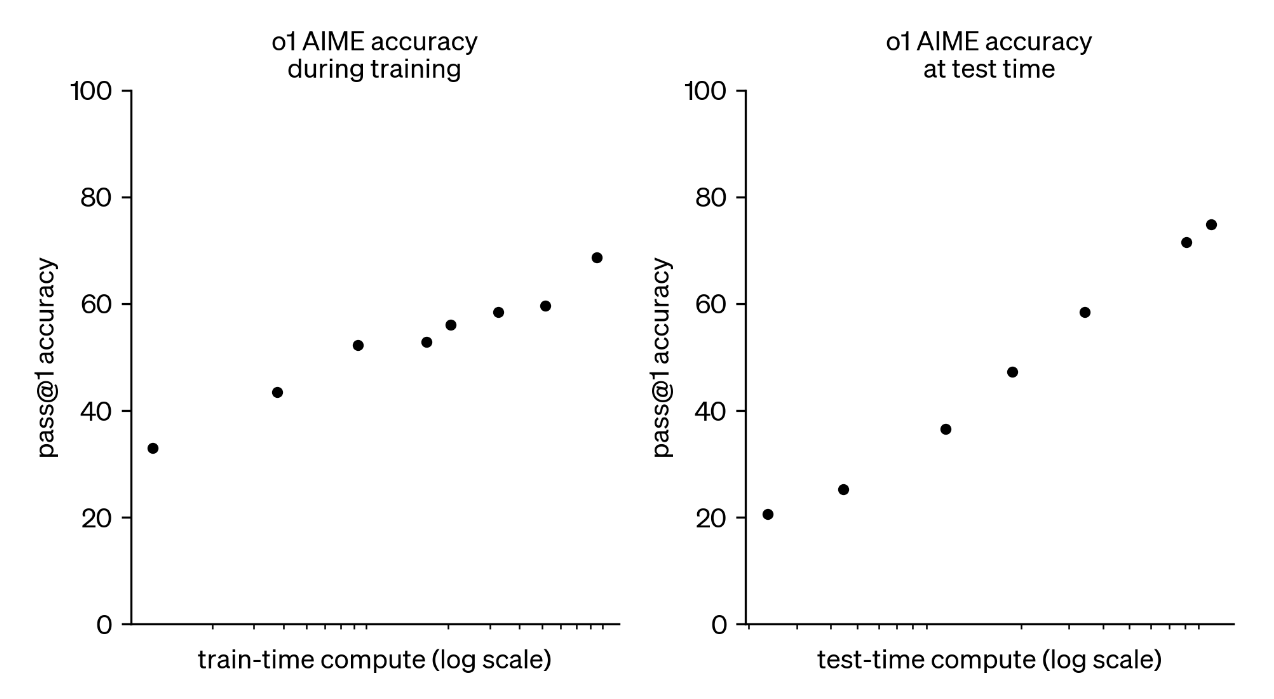
第四,是博客中给出的 Test-time Scaling Law。关键是测试时也能 Scaling!这就否定了一些网友关于 Reflection 式输出的猜测(总所周知,前几天翻车的 Reflection-70B 就是标注了大量 CoT 数据,让模型在输出时模仿更多的反思步骤,「内置 CoT」刷爆了排行榜)。如果采用这种「简单内置 CoT」的方式,是很难自由地控制 Test-time Compute 的!
People have discovered a while ago that prompting the model to “think step by step” boosts performance. But training the model to do this, end to end with trial and error, is far more reliable and — as we’ve seem with games like Go or Dota — can generate extremely impressive results.
人们早已发现,提示模型"逐步思考"可以提升其表现。但是通过端到端的试错方式来训练模型这样做,会使结果更加可靠,而且——正如我们在围棋或 Dota 等游戏中看到的那样——可以产生极其令人印象深刻的结果。
最后,是一些其他细节。这里列举出来:
- OpenAI 向用户隐藏了内在思维过程,目前网页端显示的是总结后的 CoT 过程;
- o1 的输入 tokens 计算方式与 GPT-4o 相同,使用相同的分词器;
- 网友测试,模型的思考时间时快时慢,说明其可以决定何时退出思考;
- 网友测试,模型的思考过程中,经常会有 Hmmm, Wait 这类词出现,并且在发现错误后立刻纠正;
- 网友测试,o1-mini 能够探索更多的思考链条,相较于 o1-preview(不保真);
- 网友测试,o1 对提示词更敏感,一些传统的 Prompt 策略(如角色扮演、类比举例等)反而会起到副作用,而简单让其回答效果更好(因为会默认进行思考);
- o1 系列的模型在网页端不支持修改系统提示词;
- o1 系列的模型目前不支持图像输入、函数调用、结构化输出,但是据说之后会有。

那么,OpenAI o1 背后的技术也就呼之欲出了~
- 新模型是在 GPT-4o 上进行的继续训练,具体的训练策略应该就是流传的 Self-play RL / Q*。说人话就是:让模型进行在线探索 / MCTS 采样,探索过程中给予不同路径不同的 Critic / 奖励,从中优化模型。
- 新模型在推理的时候也用了相同的策略去采样和奖励,所以会慢几倍!例如,并行采样 + 并行 Critic 反馈 + 投票 Summarize 出最终输出,理论上至少是三倍时间,多倍推理成本(o1 相比 4o 提高了 6 倍,o1-mini 相比 4o-mini 提高了 20 倍,也很合理,更弱的模型就采样更多次)
- Critic 反馈的过程中,Action Model 和 Critic Model 可能会有多轮交互(Retry),并最终由 Critic Model 或 Summarize Model 决定是否退出。因此时间会大于三倍,并且根据问题的复杂度上升!
相关论文
附上一些可能的相关论文~ 会持续更新...
Self-Critic 相关论文:
- 标题:LLM Critics Help Catch LLM Bugs
- 链接:https://arxiv.org/abs/2407.00215
- 简介:OpenAI 的 CriticGPT,通过训练“批评者”模型来帮助人类更准确地评估由大型语言模型(LLM)生成的代码。这些批评者模型本身也是通过强化学习从人类反馈中训练出来的 LLM,能够用自然语言突出代码中的问题。研究发现,CriticGPT 在识别代码中自然出现的错误方面,比人类批评者更受青睐,并且在捕获错误方面比人类承包商更有效。
- 标题:Generative Verifiers: Reward Modeling as Next-Token Prediction
- 链接:https://arxiv.org/abs/2408.15240
- 简介:Google 出品,介绍了一种新型的验证器(Verifier),称为生成性验证器(Generative Verifiers,简称 GenRM),它通过将验证问题转化为下一个词(next-token)预测任务来提高大型语言模型(LLMs)的推理性能。这种方法与传统的基于判别式分类的训练不同,它充分利用了预训练 LLMs 的文本生成能力。
- 链接:https://arxiv.org/abs/2408.15240
MCTS & Self-Improve 相关论文:
- 标题:Recursive Introspection: Teaching Language Model Agents How to Self-Improve
- 链接:http://arxiv.org/abs/2407.18219
- 简介:提出 RISE 递归自省,目的是提高模型在测试时连续尝试的响应的最终正确率(Test-time self-improve)。为此,将连续响应建模为 MDP,用 BoN 或者强模型的输出构造训练。
- 标题:Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers
- 链接:http://arxiv.org/abs/2408.06195
- 简介:提出 rStar,增强 MCTS 的 action space,同时用同一个模型验证生成的每个轨迹,类似 Self-Verify。
- 链接:http://arxiv.org/abs/2408.06195
- 标题:Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
- 链接:http://arxiv.org/abs/2406.14283
- 简介:学习 Q-value 模型作为预估奖励的启发式函数,指导 LLM 搜索并选择推理步骤。
- 链接:http://arxiv.org/abs/2406.14283
- 标题:AlphaMath Almost Zero: process Supervision without process
- 链接:http://arxiv.org/abs/2405.03553
- 简介:将 Alphago 自我对弈阶段的思路引入 Math,不需要人工标注的解题中间过程,使用 MCTS + 过程奖励估算。
- 链接:http://arxiv.org/abs/2405.03553
- 标题:Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
- 链接:http://arxiv.org/abs/2402.05808
- 简介:ICML 上的一篇论文,提出 R^3 训练框架,逆向课程学习,仅使用结果监督的信号来模拟过程监督的效果。
Test-time Scaling Law 相关论文:
- 标题:Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- 链接:https://arxiv.org/abs/2408.03314
- 简介:Google 出品,研究了 LLM 中推理时间计算的 Scaling Law,回答了以下问题:如果允许 LLM 使用固定量的推理时计算量,那么它能在多大程度上提高其在具有挑战性的任务上的性能?
- 链接:https://arxiv.org/abs/2408.03314
- 标题:An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models
- 链接:https://arxiv.org/abs/2408.00724
- 简介:探讨了在有限计算资源下,如何配置 LLMs 以实现最优的推理性能。实验表明,使用 REBASE 算法的较小语言模型(如 Llemma-7B)在计算资源减半的情况下,能够达到与较大模型(如 Llemma-34B)相当的准确性。
- 链接:https://arxiv.org/abs/2408.00724