OpenAI o3 与 Monte-Carlo 思想
本文最后更新于:2025年4月14日 晚上
o3 来了,分享一些个人的浅见。关于 Test-time Scaling Law 的进展,比我们想象中的要快得多。但我想说的是,这条路其实有些曲折——它是 OpenAI 在追求 AGI 的道路上,采取的曲线救国之策。
强化学习与捷径思维
为什么会这样说呢?我们通过两个例子来探讨。
第一个例子来自强化学习。在 RL 中,折扣因子 \(\gamma\) 扮演着关键角色,它意味着越往后的决策步骤,所获得的奖励将会逐渐减少。因此,强化学习的目标通常是尽量以最短的时间和最少的步骤获得最大化的奖励。这种策略的核心,是强调「捷径」,即尽可能快速地得到回报。
第二个例子是大模型的微调过程。一个未经微调的预训练模型,往往没有明确的指向性和控制能力。当我们询问模型「中国的首都在哪里?」时,它可能会先说「这是一个好问题!」,然后绕着话题扯一大堆,而最终才给出「北京」这个答案。然而,当同样的问题问到一个经过微调的模型时,答案直接而明确:「北京」。
这种微调后的模型展示了一种通过优化策略获得捷径的方式——与人类的进化历程相似——总是在追求最少的能量消耗和最短的路径。
为什么是 Reasoning?
如果把 Reasoning 采样的过程可视化为一棵树:
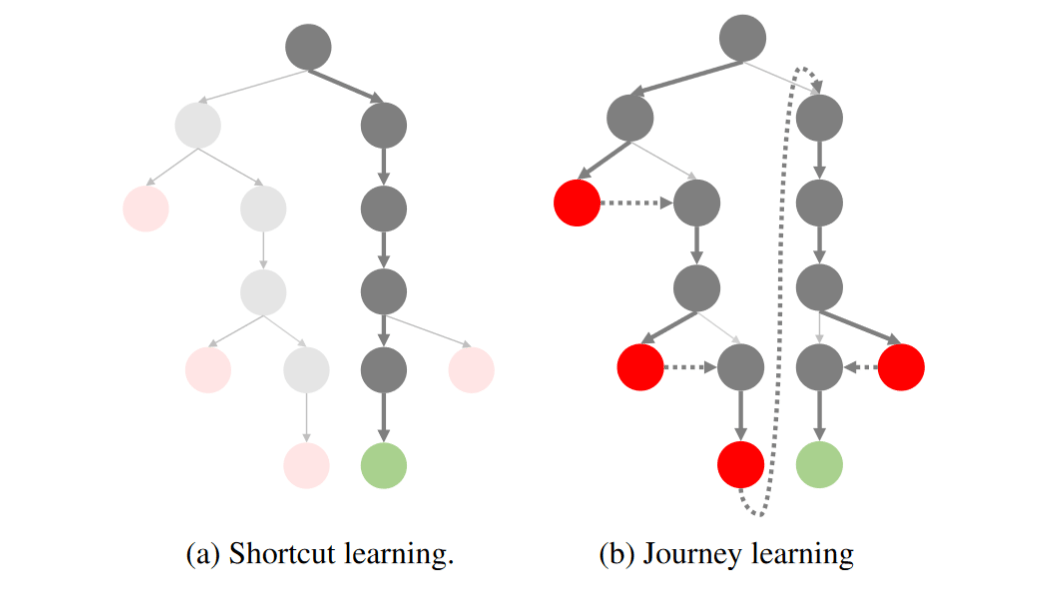
左侧的是过去我们追求的捷径学习:以最少的步骤到达正确结果。而右侧则是以 OpenAI o1 为代表的「反思、回溯」范式。
我们知道,在 o1 进行搜索的过程中,模型会进行不断的反思和回溯,而这一过程往往伴随着额外的开销。问题是,如果模型真的能一遍给出正确答案,谁还愿意花时间、花钱去做复杂的搜索呢?OpenAI 也不傻,大家都知道捷径更好!
对于越困难的问题,这棵潜在的思维树就越宽、每一步的搜索空间就更大,走捷径能到达正确答案的概率就越小。那怎么办呢?一个直观的思路就是去剪枝!把那些不可能到达终点的树节点提前剪掉,压缩搜索空间——让这棵树变回窄窄的。这也是当前许多工作努力的方向,比如:
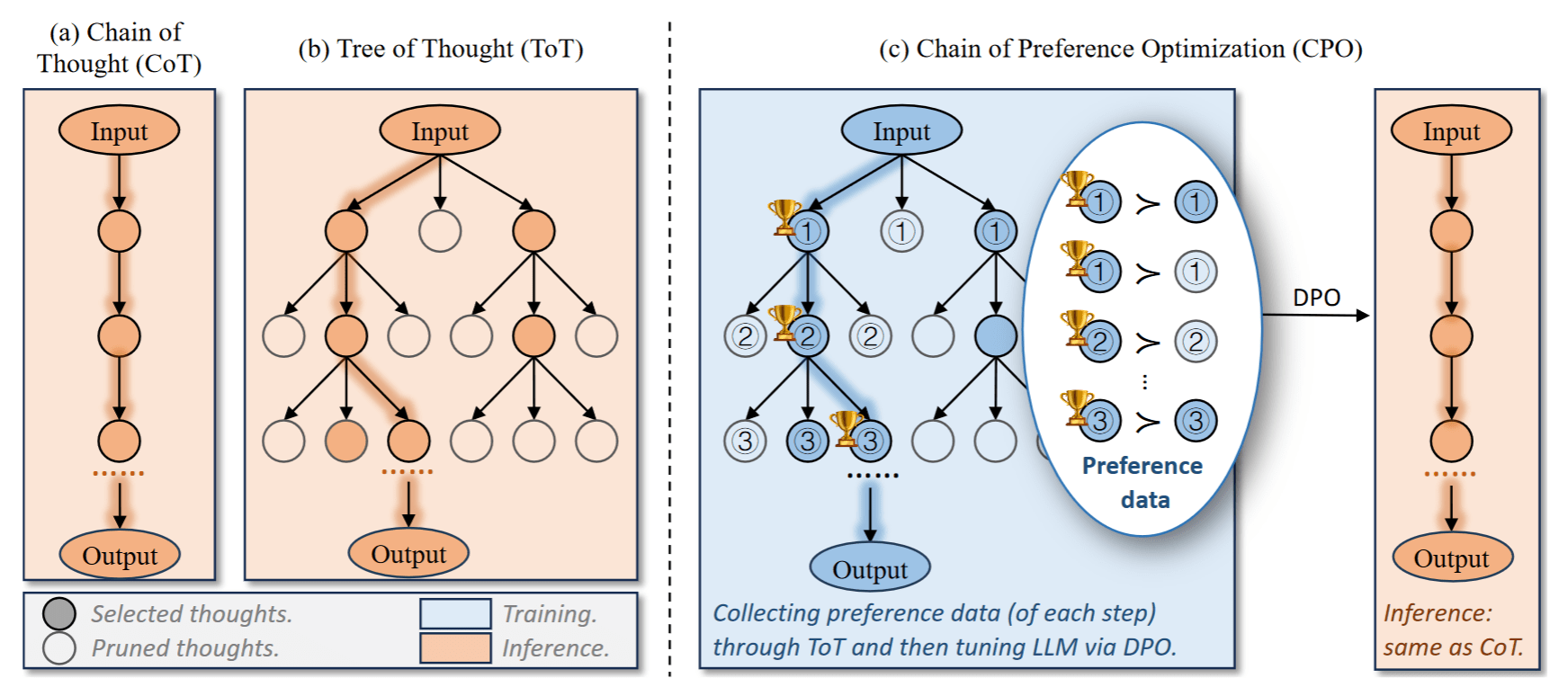
Chain of Preference Optimization 就是从思维树上天然地构造出偏好数据,再用 DPO 去优化,让模型有更大概率去选择能到达终点的树节点。
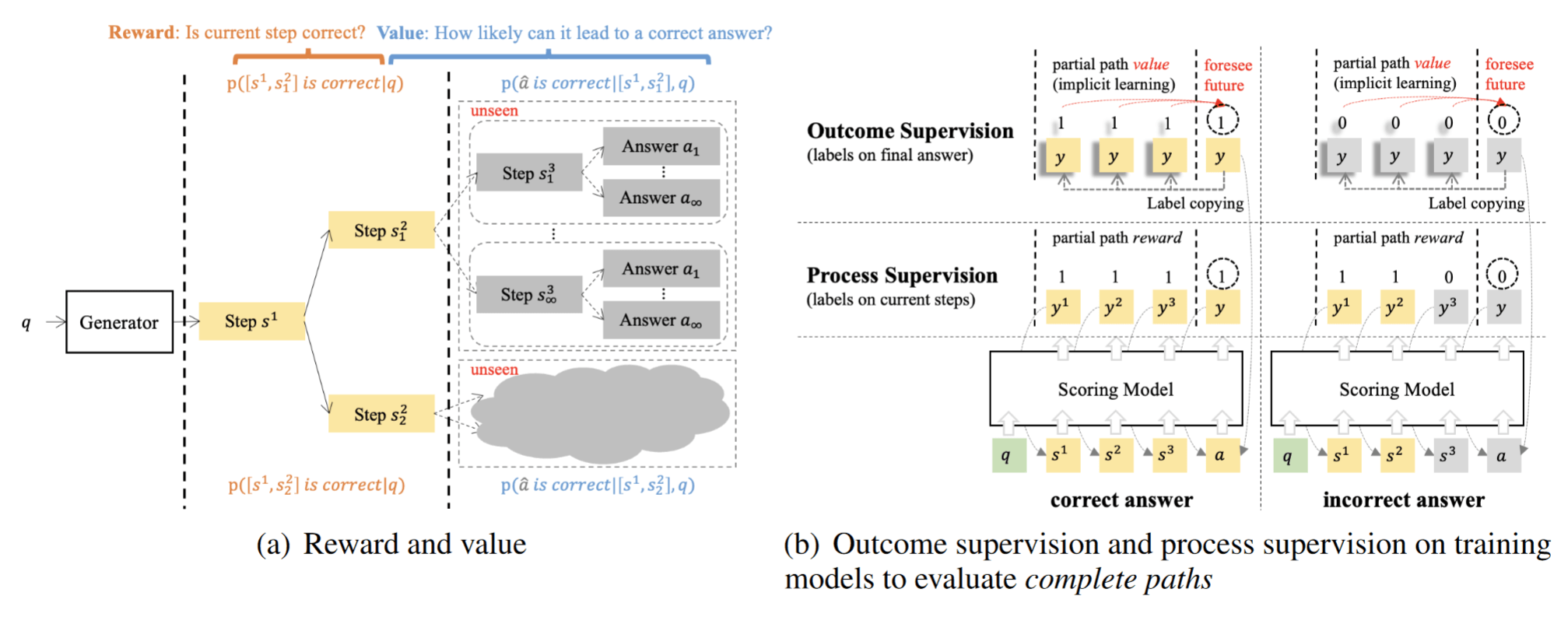
Outcome-supervised Value Models 就是将 Reasoning 建模为 MDP 过程,用当前步骤到达正确答案的概率(Value)来指导策略优化。
为何 OpenAI 选择突破传统捷径?
回到 o1 上,为什么选择打破传统的捷径思想,去走 Tree Search 这条 “弯路” 呢?
如果说在过去,我们倾向于利用(Exploit)模型的基本能力,就会认为现有 GPT-4 模型已经能够满足大部分对话和简单推理需求。并且这些任务能够很好地采样、评估偏好、迭代优化。
但这一视角忽视了更复杂任务的需求——例如数学推理(AIME、Frontier Math)、代码生成(SWE-Bench、CodeForce)等,这些任务往往难以在短期内获得回报——它们的奖励是非常稀疏的,只有在最终得出正确答案时,回报才会显现出来。
因此,传统的捷径学习不再适合处理这类复杂任务:你连一条正确路径都采样不到,何谈去优化模型选择正确路径的概率呢?
回到本文的标题中的「Monte-Carlo 思想」,我们可以发现这其实是一回事:蒙特卡洛方法在强化学习中的应用,核心在于通过多次采样来估计策略的价值,进而优化模型。然而,这一方法有天然的局限性——如果采样的策略无法采样到最优路径,那模型优化的终点永远只是局部最优。这也是为什么我们会在 MC Learning 中选择更具有探索性的策略。
于是 OpenAI 选择打破强化学习的天平,摆脱了传统的捷径思维,转而强化探索(Explore)。
o1 的突破:从探索到优化
在这一背景下,OpenAI 提出了 o1 范式。这一改变使得模型能够在面对复杂任务时,开始逐渐能够获得稀疏的奖励了!并且通过这些奖励,可以不断地优化策略。尽管这一探索过程可能显得繁琐和低效,但它为模型的进一步优化奠定了基础。
那么 o1 是怎么来的呢?最近也出现了很多复刻 o1 的工作,他们都在做什么呢?如果用于探索的行为策略是 On-Policy 方法的话,那就是用当前模型(例如 GPT-4o)去采样,效率还是太低。
于是大伙不约而同地选择了 Off-Policy 方法:
- OpenAI 花重金聘请在读博士生来标注 Long CoT 数据;
- 没钱咋办?那就搞点人机协作标注数据(人工蒸馏 o1),降低对标注者的要求;
- 连找标注者的钱都没有?那就只能去蒸馏 R1 / QwQ、或者想其他的办法(Critique、PRM 等)。
这里我也想提醒积极复刻 o1 的大厂、实验室们,不要忘了:探索的终极目标还是优化!
插一句题外话,虽然大家都在骂 o1 隐藏了真正的思维链,只展示 Summary 的捷径版本。殊不知这个 Summary 才是优化策略的关键数据!但 OpenAI 并不害怕其他人蒸馏这些 Summary,因为蒸馏这些数据还有一个前提——基础模型的能力足够强大,不然步子迈太大还容易闪了腰。
并且 OpenAI 还将探索的成本转嫁给了用户。虽然在初期花很多钱来标注探索型数据,但现在有了 o1 后,用户使用的过程中又无形地为他标注了更多数据。OpenAI 再次实现了伟大的数据飞轮!
o1 到 o3 的快速进化
o1 才刚发布没几个月,o3 就来了。
其实这也侧面验证了前面的猜想:如果说 GPT-4 代表了从 0 到 1 的进步——即从简单任务到获得奖励的过程;那么 o1 则代表了从 1 到 10 的飞跃——通过探索复杂任务并获得稀有的回报,为进一步优化策略提供了前所未有的高质量数据。
因此它的进展之快,超出了所有人的预期:
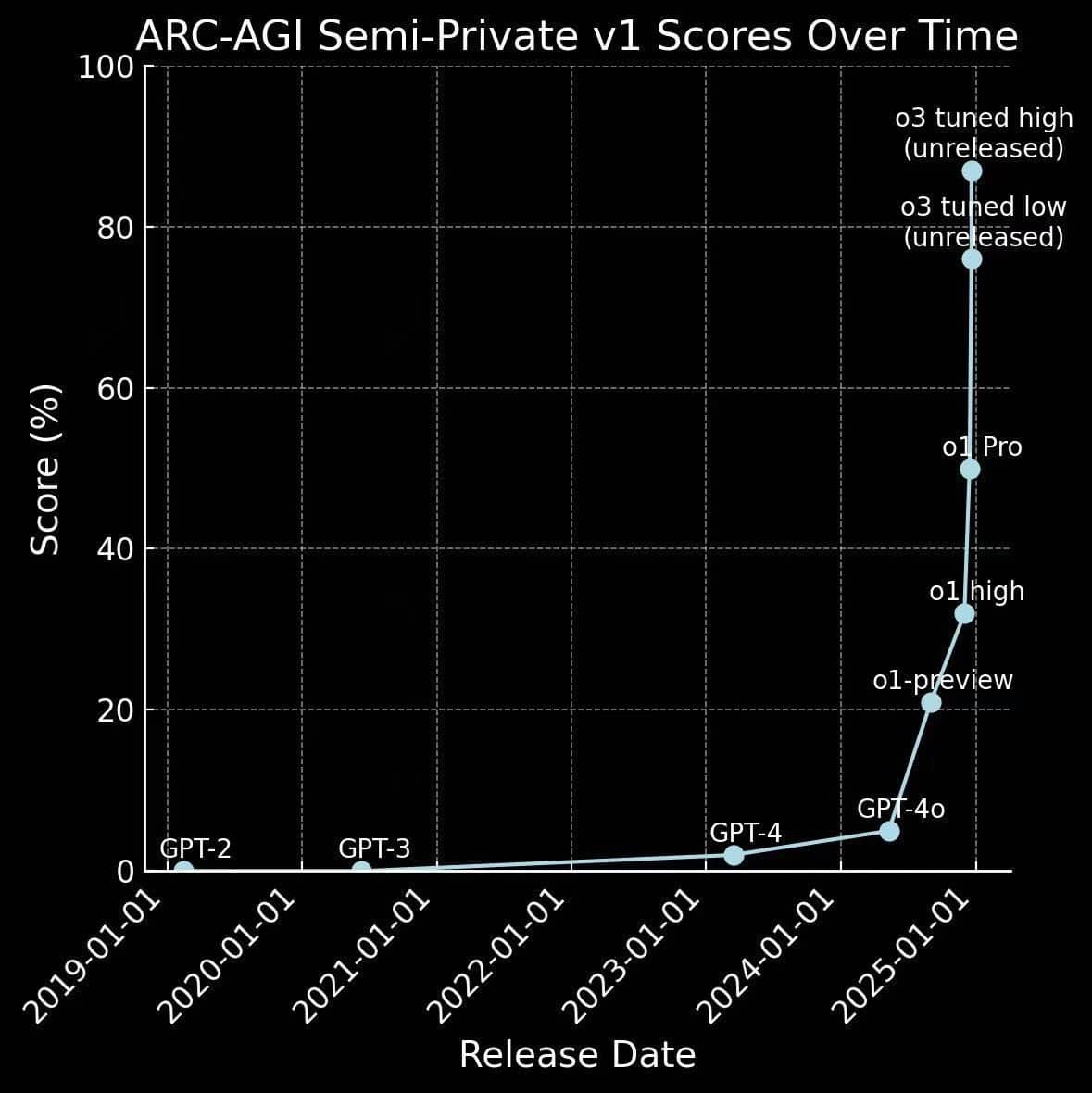
这不仅是对探索策略的成功应用,更是人工智能技术迈向 AGI 的重要一步。