IR学习笔记 #06 网络信息检索
本文最后更新于:2022年11月28日 下午
随着互联网的兴起,Web 的增多,网络信息检索成为 IR 中的一大主题。
简要介绍以下几个相关概念:
- 最广的是 Network ,一个物理层面的广义网络。
- 其次,是互联网。因特网和其他类似的由计算机相互连接而成的大型网络系统都可算是互联网,Internet 是互联网中最大的一个。
- 再者,是 Internet,即因特网。由许多小的子网互联而成的一个逻辑网,每个子网中连接着若干台计算机(主机)。
- 最后,是 Web,也称 World Wide Web,即万维网。它使用超文本技术将遍布全球的各种信息资源链接起来,以便于用户访问。Web 只是 Internet 上的一个应用层服务。
网络信息检索 | Web Search
Goal | 目标
Provide information discovery for large amounts of open access material on the web.
Challenges | 挑战
Volume of material -- several billion items, growing steadily
Items created dynamically or in databases (deep web, about 150 times of web pages of surface web)
Great variety -- length, formats, quality control, purpose, etc.
Inexperience of users -- range of needs
Economic models to pay for the service -- 订阅、广告、许可
Strategies | 策略
- Subject hierarchies (分类目录) + human indexing -- 1st Generation
- Web crawling (网页爬取) + automatic indexing -- 2nd Generation
- Human directed web crawling and automatic indexing -- Mixed models
Components | 组成
- Web crawler: URL Server + Crawler + Store Server
- Indexing system: URL Resolver + Indexer + Pagerank (离线网页排名算法)
- Search system: Sorter + Searcher (在线检索服务)
网络爬虫 | Web crawler
Web crawler,也称 Web spider,用于下载网页的一种程序。只要给出 seed URLs (Uniform Resource Locator) 的初始集,就可以递归地(recursively)根据集合中的链接下载更多的页面。有两种特殊的爬虫:
Focused web crawler,针对特定类别的网站的专业爬虫,需要分类方法支持。
Deep web crawler,针对动态网页的深网爬虫,需要脚本模拟动作支持。
对于所有的爬虫,最重要的是抓取一个页面中的链接,扩充初始集。
此外,一个爬虫,还要考虑性能(爬取大量页面)、礼貌性(避免过载服务器、违法操作)、应对故障(破损链接、超时、爬虫陷阱)、搜索策略(DFS/BFS),存储网页(并行文件系统)等。
礼貌性 | Politeness
「恶意爬虫」往往会在短时间内大量访问同一个站点,造成 DDoS 攻击(Distributed denial of service attack,分布式拒绝服务攻击),进而导致网站的瘫痪。此外,还存在非法爬取私人信息、非法收集数据等行为。
为了在法律上限制爬虫,有以下的协议:
Robots Exclusion Protocol:网站管理者可以注明该网站的哪些路径是不可被爬虫访问的,这些协议会体现在 http://.../robots.txt 中。
Robots META tag:HTML 作者可以注明该页面中的文件不可被索引,或该页面不可被用于解析以获得更多链接。只需要在 HTML 文本中添加以下命令:
1 | |
爬虫性能 | Performance
爬虫面向的信息往往是极庞大的,超过了一台机器的性能范围。现实中,通常采用并行分布式爬虫,将任务量划分到各台机器。那么如何分配任务才能使得各台机器承受的压力均匀呢?
Distributing the Workload
首先可以将机器编号 0 至 N-1,再对一个 URL 的主域名(Domain name)做哈希,得到一个 0 至 N-1 的值,并分配到对应机器。这样做的好处有:
- 同一域名只在一台机器上访问,这样就可以防止多台机器同时访问了同一域名(避免对其造成 DoS 攻击)。
- 不需要主服务器的分配,减少了机器间的沟通,主域名下的子域名全在同一台机器中。
- 每台机器有独立的 DNS cache (域名缓存),可以提高查询效率。
Software Hazards
此外,要提高爬虫的性能,还要实现软件故障的处理:
- 过慢、无应答的 DNS/HTTP 服务器
- 过大、无限大的页面(自动填充型)
- 无限的链接(随时间变化的路径)
- 破损的 HTML 页面
Extract Links
抓取页面中的链接、解析页面中的链接也会遇到许多难题:
- 相对路径、绝对路径
- CGI (Common Gateway Interface, 公共网关接口) 动态生成的页面
- Server-side 服务端脚本
- 隐藏在 JavaScript 代码中的链接
爬虫架构 | Crawler Architecture
接下来介绍一种经典的分布式爬虫架构 High performance large scale web spider architecture。
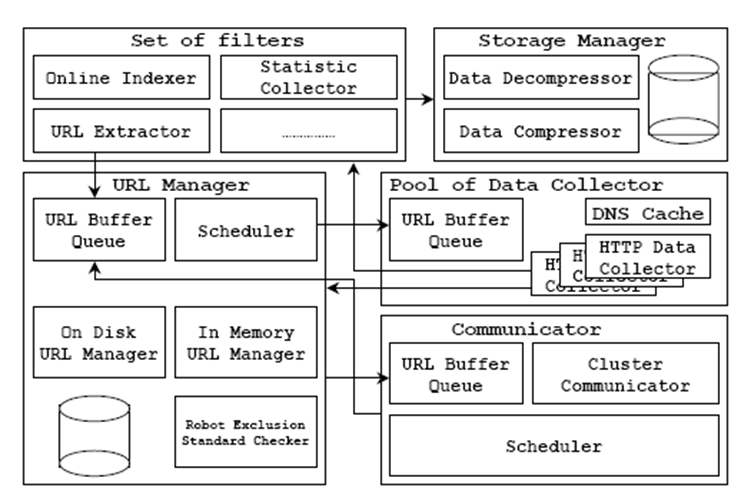
- URL Manager
存放所有访问过的 URL 记录,以及待访问队列。
- Pool of data collector
数据收集池,按照 URL Manager 分配的序列访问网页,内部通常由多台机器多线程地收集网页数据。
- Set of filters
实现数据统计、页面索引、链接提取的功能,并返回新的连接到 URL Manager。
- Storage manager
负责压缩、解压缩、存储、检索数据。
- Communicator
通信器,将新找到的页面和找到它的页面连接,完成 URL 去重等任务。
URL 队列 | URL Frontier
URL Frontier 维护了一个包含大量 URL 的队列,并且每当有爬虫线程寻找 URL 的时候,它都会按照某种顺序重新排序。以何种顺序返回队列中的 URL,需要有两个方面的考虑:
- 第一个要考虑的是具有很高更新频率的高质量页面,即页面的优先级。一个页面的优先级权值应该是由它的改变频率和它本身网页质量(使用一些恰当的质量评估方法)共同决定的。
- 第二个要考虑的就是礼貌策略:我们必须避免在很短的时间间隔内重复抓取同一个主机。因此,如果URL队列被设计成简单的优先级队列的话,可能会造成对某一主机的大量的访问请求。
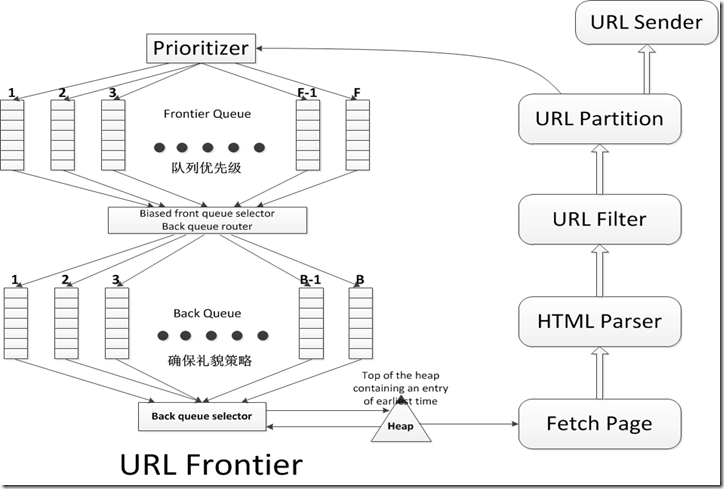
上图展示了一个基于礼貌性和权值策略的URL队列的实现。它的目标是确保:
- 每次只有一个连接去访问一台主机;
- 连续对同一个主机的访问请求之间存在几秒钟的等待时间;
- 具有高优先级的页面将会被优先爬取。
其中有两个重要的子模块,前部分的 Front 队列集合 F,以及后部分的 Back 队列集合 B。这两种队列均是 FIFO 队列。
Front 队列实现了对权值相关处理,而 Back 队列实现了对礼貌策略的相关处理。在一条 URL 被添加到队列的过程中,它将会先后穿越 Front 和 Back 队列。
首先,权值计算器会给该 URL 分配一个介于 1 和 F 之间的整数权值,再进入相应的 Front 队列,具有很高更新频率的文档(如新闻页面)将会被赋予一个很高的权值(通过启发式方法)。而后高权值对应的 Front 队列也会更高频率的吞吐 URL。
此外,我们需要维护一个堆,堆里存放着的条目对应每一个 Back 队列,该条目记录着该队列所对应的主机可以再次被连接的最早时间。注意:每个队列仅对应一个主机,即满足分布式的要求。
请求获取 URL 的爬虫线程会抽取出堆顶元素(时间最早者),然后一直等到相应时间后访问之。从而避免访问频率过高。