IR学习笔记 #08 倒排索引模型
本文最后更新于:2022年11月28日 下午
文件组织架构,也称 index (索引),常用于提升一个检索系统的性能。
回顾向量空间模型,我们知道在查询时,命中的 doc 应该是与 query 最为相近的几个向量。当查询时,若只在所有可能相似的文档(至少含有一个 query 中的关键词)中查找,可以大大减少资源浪费。
那么就需要先得到 query 中各个 term 出现过的文档,再取并集,最后在并集中进行相似度的计算——「过滤」思想。
此时用特殊的索引方式,就可以更快地实现文档的过滤。有人提出 Hash 的设想,但是 Hash 的缺点在于不能模糊匹配,当用户的 Query 和词典中的 term 略有差距时,可能在 hash table 中会相距十分遥远。
倒排文件 | Inverted Files
我们通过一组对比,引入「倒排」的概念:
- 正排索引:已知文档 doc,得到 doc 的 所有 term 的位置序列,实现方式是「文档编号 + term 数组」
- 倒排索引:已知 term,找到包含 term 的文档 d1, d2, d3... 实现方式是「term做键的字典,值是文档编号数组」
由此我们可以得到倒排文件组织架构的构成:
- Index file:索引文件,以词典(Lexicon)的形式存储词项,链接到 Posting file 的空间。
- Postings file:记录文件,以倒排表的形式存储每个 term 对应在 Doc file 中的df、tf、DocID、pos 等相关信息。
- Document file:文档文件,存储所有文档。
有了上述的架构,当用户输入 query 时,我们可以提取出 term,直接访问对应的 Index file,再根据链接来到 Posting file。对于多个 term,可以先完成交、并等逻辑运算,得到结果后,再去访问过滤后的文档集。
构建倒排文件
由此,我们可以知道当爬取到新的文档时,构建索引的步骤:
- Tokenizer:提取 token 流。
- Linguistic modules:规范化,得到 term 集合。
- Indexer:在对应的 term 键值下新增该文档的编号。
文档解析 | Document Parsing
接下来介绍搜索引擎如何解析一个新爬取到的文档,这个过程往往是离线进行的(在线进行的是用户查询过程)。
而由于文档的多样性,往往解析过程中会面临各式各样的问题:文件格式、各国语言、字符编码、停用词等。这些问题往往用启发式(heuristically)的方法解决。
- 断词、标记化 | Tokenization
Token 来自文档的原始字符串,是根据空格划分提取出的原始单词。在实际中,要考虑:是否保留 's 、是否保留连字符、专有名词是否拆开、数字嵌入等子问题。
而针对不同语言,也有更多新的问题:法语中大量的 ' 使用、德语中名词复合现象、中文日文不适用空格分词、日语的平假片假、阿拉伯语的书写次序等。
- 停用词 | Stop words
在文本中,往往还需要把最频繁出现的无意义词停用。在文档解析中,如何利用停用词进行压缩空间?在查询优化中,如何判别停用词?当停用词有意义时,如何识别?这些都是需要考虑的问题。
- 标准化词项 | Normalization
在英语中,通常时以定义「等价集」(equivalence classing)来归并词项。通常将单词归并到其原型,而对于特殊的单词有特殊的规则,例如规定 “U.S.A.” 归并于 “USA”,规定 “anti-discriminatory” 归并于 “antidiscriminatory”。
对于有的单词,不同形式可能含有不同语义,例如 window/windows/Windows。此时在查询时可以先做不对称展开(asymmetric expansion),对展开项搜索后取并集。
- 辞典和探测法纠错 | Thesauri & Soundex
主要针对 Synonyms (同义词)、Homonyms (同形同音异义词),这种情况下也可以利用等价集和不对称展开解决。
此外,当用户查询中有英文拼写错误时,常用的方法是 Soundex (探测法),返回同音字串。Soundex 是基于语音启发式方法生成的语音等价集。这种方法在汉语拼音中同样有很大应用。
- 词干分析与词形还原 | Stemming & Lemmatization
将单词的名词、动词、形容词等形式统一归并到词根,将单复数、人称所有格、时态等统一归并到原型。
文档文件 | Document file
解析完文档后,我们可以将新的文档直接存入文档集,也可以利用摘要生成技术生成 Surrogates (文档替代品),减少存储空间。
此外,当我们搜索到页面文档时,其文件格式可能各不相同,如 HTML、XML 等,故检索到网页后还需要进行 Page Purifing (文档净化),从而获得便于识别的文本文档和内部链接。
记录文件 | Posting File
之前的文章介绍过,用于连接 term 和 doc 的词典表往往是个稀疏矩阵。而倒排文件用链表的形式存储每一行的内容,即包含此 term 的所有 doc 及其基本信息,串接而成。链表中的每个元素称为一个 posting (记录)。
其中,基本信息可以包含:Document ID (文档的唯一标识)、Location Pointer (该文档在 Doc file 中的位置)、原始的权重因子。
存储原始的权重因子,是为了在查找的时候更方便的计算词项权重。可以包括 df、tf、最大频度、总文档数等等。
此外,链表中的元素以 Doc ID 排序,这样存储有利于多页倒排表的合并匹配。
索引文件 | Index File
索引文件通常以词典的形式存储 term ID、含有该 term 的文档数以及该 term 在记录文件中的位置(指针)。
以下列出几种常用的索引文件组织形式:
Linear Index | 线性索引
Binary Tree | 二叉树
Right Threaded Binary Tree | 右索二叉树
B-trees | B树
B+-tree | B+树
Tries | 搜索树
特征选取 | Feature Selection
前文提到,在解析一篇文档获得索引时,最简单的方法就是先提取 token,再获得 term 作为索引。而在真正高效的索引模型(Index Model)中,往往要先对文档进行特征选取,从而构成索引。
而特征选择问题,可以转化为词项权重(term weighting)计算,一篇文档中权重较大的 term 往往更能表示这篇文档。
词项频率 | TF
在前面的文章中有提到,tf 及其衍生的权重计算方法,是 IR 模型中最常用的权重计算方法。这里就不再重复介绍,仅提及一个有趣的定理 Zipf's Law。
该定理描述了如下现象:在一个大的文档集中,统计出各个词项的 tf 排名后,记排名为 r,频率为 f,则有 \[ f\cdot r\approx \mathrm{const} \] 而在实际中,排名最高的词项通常都是停用词,最「重要」的词往往词频不是很高,而最罕见的词往往没有普遍价值。这也与 tf·idf 的思想契合,下图说明了这一点。
在倒排文档中,移除停用词和罕见词、保留重要词,可以节约大量的记录空间。
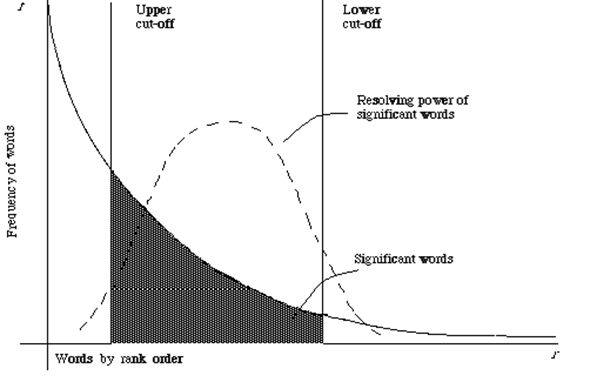
索引规模 | Index Scale
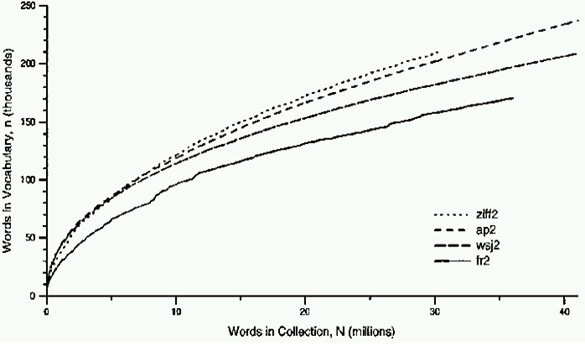
对于一个确定大小的文档集,需要多少词项才能很好的索引全部文档呢?这便是根据文档集大小确定词典大小(Lexicon Size)的问题。Heap's Law 对此进行了估算: \[ n=|V|=K \cdot N^{\beta} \text { with constants } K, 0<\beta<1 \] 其中,K 通常取 10 到 100 间的整数,\(\beta\) 通常取 0.4 到 0.6 之间的小数。绘制出的图如下:
词项判别模型 | Term Discrimination Model
在一个向量空间中,文档由基向量加权构成的向量表示。
我们可以计算文档之间的相似度,相似度越高,代表空间越紧凑,反之则越松散。计算文档集两两之间的相似度需要 \(O(n^2)\) 的复杂度。
当然,如果先计算出一个「平均文档」,再计算其他文档与其的相似度,则只需要 \(O(n)\) 的复杂度。
词项判别模型则是通过引入一个新的 term 作为基向量,观察相似度的变化分析该 term 的重要性。大致的思想是:
- 如果一个 term 引入后,向量空间变松散了,则说明这个 term 有效的区分了不同文档,这个词通常是中频词(重要词)。
- 如果一个 term 引入后,向量空间没有变化,则说明这个 term 没有太大价值,这个词通常是低频词(罕见词)。
- 如果一个 term 引入后,向量空间变紧凑了,则说明这个 term 将文档同一化了,这个词通常是高频词(停用词)。