IR学习笔记 #07 IRLbot
本文最后更新于:2022年11月28日 下午
本文是 WWW2008 最佳论文「IRLbot: Scaling to 6 Billion Pages and Beyond」的阅读报告。相关领域:网络信息检索。
摘要
随着验证 URL 唯一性的复杂度平方增长、BFS 爬行顺序和固定的每主机速率限制,现有的爬虫算法不能有效地应对在大型爬虫中产生的大量 URL、高度分枝的垃圾页面(highly-branching spam)、数百万页博客站点以及服务器端脚本(server-side scripts)产生的无限循环。作者提供了一组处理这些问题的技术,并在称为 IRLbot 的实现中测试它们的性能。
关键词:IRLbot, large-scale, crawling
问题提出
作者称本文不是针对数据挖掘器,而是致力于设计能够适应当前和未来网络规模的网络爬虫:从一个给定的 seed URL 集合开始,递归地访问集合中的页面,并在这个过程中动态地改变下载顺序,最终可以下载到所有有用的网页;同时,在下载的过程中,无论规模多大,都应当保持一定的速度。
当然,还有以下考虑:爬虫需要限制对于单一网站、单一服务器的访问频率(礼貌策略),避免陷入垃圾网站和服务器端脚本产生的无限循环。
具体而言,作者提出了三类问题:
规模扩展问题 | Scalability
每个爬虫系统都必须面对一个固有的取舍:在处理规模(scalability)、性能(performance)和硬件资源使用(resource usage)三者中做出权衡。
一般来说,较大的规模将导致较低的性能与较高的资源使用,较高的性能需要降低规模与增加资源使用。因而,大多数爬虫只能兼顾三者之二(大型慢速爬虫、小型快速爬虫,大型快速却需要占用大量资源的爬虫)。
本文希望在给定性能标准和硬件资源的情况下,研究规模的扩展问题。
网站信誉与垃圾网站问题 | Reputation and Spam
与早期的网络相比,如今的网络已发生了很大变化,主要是在服务器端脚本生成的动态网站和垃圾网站两个方面。二者性质不同,却都给爬虫带来了一个新的挑战:必须要有一种在爬虫爬取网页的过程中实时决定哪些站点包含有用信息、实时决定爬取优先级的方法。
因为,传统的广度优先搜索往往会由于以下原因而降低效率:
- 来自垃圾网站 URL 分支过多,甚至可能取代合法的 URL;
- 单个域名中动态创建新主机名,DNS 解析不及;
- 来自网页的延迟攻击,故意在来自爬虫程序 IP 地址的所有请求中引入 HTTP 和 DNS 延迟。
礼貌问题 | Politeness
网络爬虫对某一服务器的频繁访问,往往会对服务器的正常性能造成影响,因而也容易招致服务器的拒绝访问或是举报、诉讼,因而需要对爬虫设置一定速度的限制。
直接给爬虫设置这种对单一服务器、单一 IP 地址的访问速度限制并不复杂,却容易导致爬虫的效率在特定情况下(待爬取的 URL 只来自于极少的几个服务器或 IP,由于限制不得不减慢速度)极大地降低效率。
因而需要设计一种可以避免这种情况的发生的爬虫。
解决规模扩展问题
磁盘检查算法 | Disk-check Algorithms
规模问题最终体现在使用 URLseen 确认 URL 的唯一性和使用 RobotsCache 检查 robot.txt 的符合上。此外,还要将新的 URL 再传递给 URLseen ,以及在必要时更新 RobotsCache。主要牵涉到磁盘与存储器的交互。
在先前的方法中,无论是使用 RAM 散列存储的 Mrcator-B,还是使用内存中二叉搜索树的 Ploybot,随着爬取规模的增大,执行这一步骤的开销都会快速增长。为了降低这一开销,需要一种更有效的数据存储结构。
DRUM - Disk Repository with Update Management
论文中提出了 DRUM 技术,这个技术结合了桶排序和哈希算法。
DRUM 的目的是允许高效地存储大量 <key, value> 对的集合,其中 key 是某些数据的唯一标识符(hash),value 是附加到密钥的任意信息。通过这样的设计,可以实现对大规模键值对数据的存储,并实现快速的检查(check)、更新(update)、检查+更新(check+update)的操作。
下图展示了 DRUM 的操作流程:
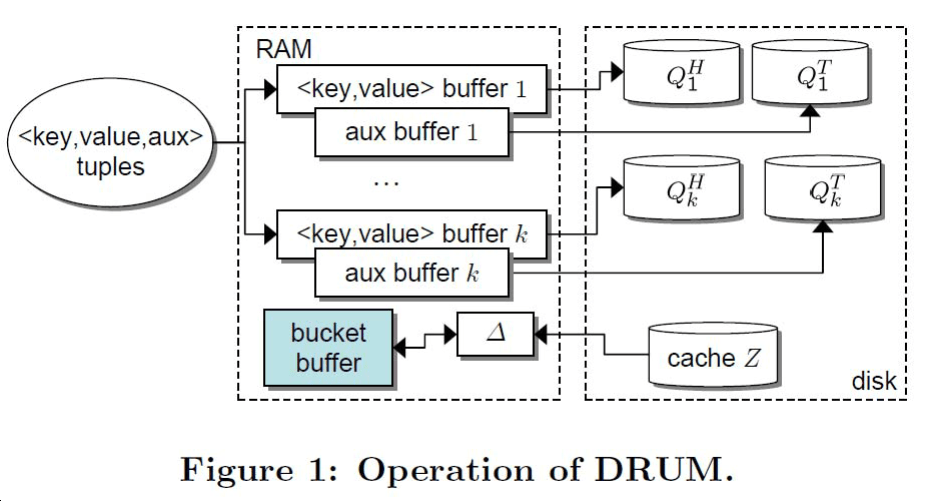
在该图中,一个连续的元组 <key, value, aux> 流到达了 DRUM,其中 aux 是与每个键相关联的一些辅助数据。随后被分割为 <key, value> 与 aux 两个部分,分入内存中的各桶,并在一次操作中将所有的桶中的 <key, value> 与磁盘存储阵列中的数据进行合并。此外,通过读取 cache Z 中的 \(\varDelta\) 字块,并与桶中的 key 比较,可以确定其唯一性。
利用这一技术,在论文中的爬虫系统创建了多个存储模块,包括 URLseen 模块、RobotsCache 模块、RobotsRequested 模块、PLDindegree 模块,分别赋予元组一定的意义,赋予各模块特定的操作,以此大大提高系统规模化的效率。
性能分析
论文中主要通过给定一系列参数来推导 URLseen 的开销,从而比较各种数据结构的优劣。参数定义及推导过程详见论文。
Mrcator-B: \[ \omega(n, R)=\frac{2(H+P) p H}{R} n^{2} \] Ploybot: \[ \omega(n, R)=\frac{2(b+4 P) p b q}{R} n^{2} \] DRUM:(论文中公式有两种情况) \[ \omega(n, R)=n b\left(\frac{(H+b)(2 U H+p H n)}{b D}+2+p+\frac{2 H}{b}\right) \] 并做出了如下比较:
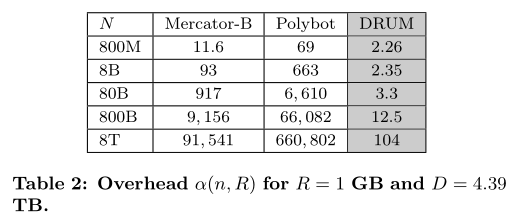
可以看出 DRUM 模型的效率远超过原来两个模型。此外论文中还针对磁盘性能和平均爬虫效率(下载速率)做出了比较,这里不再赘述。
解决垃圾网站问题
计算站点信誉 | Computing Domain Reputation
拥有大量动态网页的合法网站与制造大量垃圾网页的恶意网站(quickly branching site),都使得爬虫在礼貌性原则、DNS 查找以及爬取本身的限制下变得低效,也会浪费带宽下载许多无用的内容。
然而,由于互联网规模不断扩大,拥有同样有用大量网页的合法网站与恶意网站相互混杂,使得简单的限制分支因子或限制每个域名的最大 pages/hosts 数量,并不能合理的解决这个问题。而在之前的研究中,无论是 BFS 的爬取策略,还是 PageRank、BlockRank、SiteRank 算法,也极易使爬虫陷入到这种海量网站中。
事实上,严格的页面级排名对于控制大量分支垃圾网站并不是绝对必要的。作者发现可以通过根据域名信誉来判断网页类型、决定对某一域名的网站搜索的深度,域名信誉是根据垃圾网站必须付费的域名资源程度来确定的。
STAR - Spam Tracking and Avoidance through Reputation
论文指出,只要在「域名信誉」的基础上给每个 PLD (Pay-Level Domain) 分配「预算」,即可侦测出垃圾网站。论文在 PLD 这个较粗的粒度上进行“预算”的计算,流程如下图:
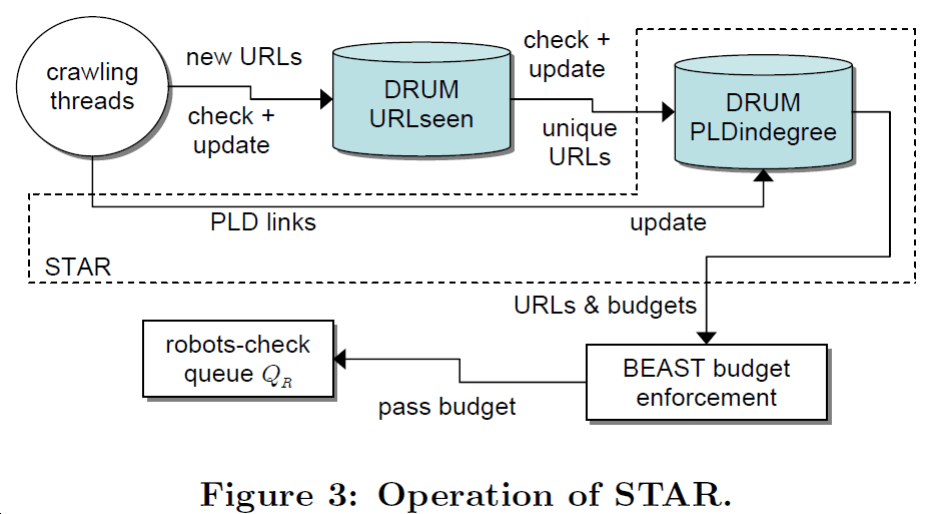
利用 DRUM 的存储结构,存储爬虫在爬去过程中得到的 PLD 网络图的信息,构造 PLDindegree 模块。通过模块中考察域名的链入数,为各个域名动态地分配“预算”,并按照“预算”指示单位时间内爬虫能够从该域名爬取多少新的链接,最终避免垃圾网站的困扰。
性能分析
从理论上说,从其他 PLD 获得链入需要付出(金钱)代价,一般的垃圾网站在代价面前很可能不会获得高的“预算”,故使用这一方法来鉴别网站的质量。
解决礼貌问题
速率限制 | Rate Limiting
IRLbot 从一开始的主要目标之一就是在访问配置不佳(就带宽或服务器负载而言)的站点时遵守严格的速率限制策略。尽管较大的站点更难崩溃,但不受限制的访问频率往往也会被视为 DOS 攻击。
而在之前的研究中,简单地设置单个主机的访问延迟,可能会导致“多主机共用”的托管服务器崩溃,若设置单个服务器的访问延迟,又将大大降低效率,甚至可能在大规模的网页中最终无法正常工作。
另一方面,在已经得到各网站“预算”的情况下,若仅仅只是重复地扫描未爬取的链接队列并从中选取需要爬取的链接,只能在高昂的花费下得到极少的有用链接。因而需要想办法更有效地利用“预算”的结果给出爬取各网页的延迟,才能实现高效的爬虫。
BEAST - Budget Enforcement with Anti-Spam Tactics
此方法的目标不是丢弃 URL,而是延迟它们的下载,直到更多地了解它们的合法性。
大多数网站的排名较低是因为它们没有权重高的链入,这并不一定意味着它们的内容是无用的,或者它们属于垃圾网站。在所有其他条件相同的情况下,排名较低的域名应该以某种近似循环(round-robin)的方式爬取,并谨慎控制它们的分支。
此外,随着爬取的进行,域名会改变它们的声誉,而先前未通过预算检查的 URL 需要重新计算预算,并且以不同的速率爬取。
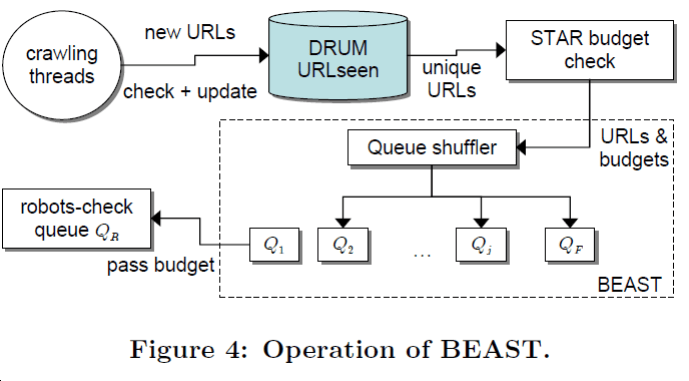
如图所示,在经过修正之后,论文给出了一种不需要依赖数据规模增大硬盘读写能力的实现方式:
将通过 STAR 赋予了一定预算的成批链接进行检查,将通过检查的、有较高预算的链接按照预算排名高低分到 j 个队列中,将暂时未通过检查的、只有排名的链接分到一个单独的队列 \(Q_F\) 中;当前 j 个队列中的链接全部爬取完成后,重新检查队列 \(Q_F\),并将其中通过检查的链接分到已有队列的两倍数量的队列中。
不断重复上述过程,不断动态地增加队列的数量,直至达到某些停止条件。用这种办法可以合理地决定网页的爬取顺序。
性能分析
采取 BEATS 的办法,一方面保留了队列的不同优先级,使得队列 \(Q_F\) 中具有较高预算的链接可以尽快地得到爬取;另一方面利用不断增长的 j 使得预算较低的链接不断地推迟被爬取的时机,实现爬取的延迟。
实验验证
模型构建
在充分整合 DRUM, STAR, BEAST 技术之后,论文搭建形成了如图所示的爬虫系统 IRLbot。
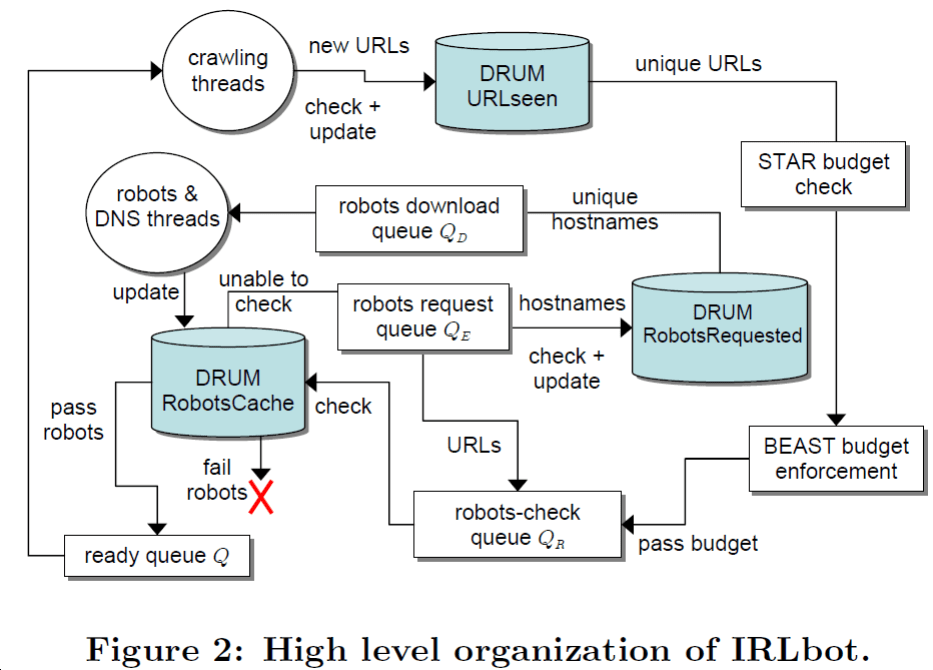
并从 crawling threads 得到新链接开始,涉及到 URL 唯一性确认,“预算”的确认,robot.txt 的确认,“预算”的检查以及最终页面的下载,形成了一个完整的处理流程。
效率验证
论文中提到,在 2007 年 6 月 9 日至 8 月 3 日的这段时间,IRLbot 运行在单一服务器上,并以 1GB/s 的速度连接互联网。最终在 41 天的运行过程中,爬取了 63 亿的页面。
此外,通过分析排名最高的 1000 个网站,发现其中的大部分网站都非常权威知名,这也说明了 STAR 信誉计算的有效性。