RL 学习笔记 #07 值函数近似和 DQN 算法
本文最后更新于:2025年3月28日 晚上
前面介绍的 SARSA 和 Q-Learning 等算法,实际上是基于表格形式(Tabular Representation)的值函数学习方法。这个表格就是所谓的 Q-Table —— 可以将 \(q(s,a)\) 放置到一个二维表格,将 \(v(s)\) 放置到一个一维表格 。尽管这些方法在小规模、离散状态空间中能够很好地工作,但随着状态空间的扩展,存储和更新表格的代价变得难以承受,且无法泛化到未知状态。
为了克服这一问题,我们需要引入值函数近似(Value Function Approximation)方法。举个例子,对于组状态 \(s_1, \ldots, s_N\),他们的状态值为 \(v(s_1),\ldots,v(s_N)\)。当 \(N\) 非常大的时候,我们尝试用一个简单的曲线来拟合他们之间的关系: \[ \hat{v}(s, \theta)=a s+b=\underbrace{[s, 1]}_{\phi^\top(s)} \underbrace{\left[\begin{array}{c} a \\ b \end{array}\right]}_\theta=\phi^\top(s) \theta \] 其中:
- \(\hat{v}(s, \theta)\) 表示对曲线的估计,这里将其拟合为线性关系;
- 为了形式的统一,我们将其写为向量相乘的形式,\(\theta\) 表示参数向量,\(\phi(s)\) 表示特征向量。
此外,我们也可以用更高阶的曲线进行拟合: \[ \hat{v}(s, \theta)=a s^2+bs+c=\underbrace{[s^2, s, 1]}_{\phi^\top(s)} \underbrace{\left[\begin{array}{c} a \\ b \\ c \end{array}\right]}_\theta=\phi^\top(s) \theta \] 这个时候 \(\hat{v}(s, w)\) 对于 \(s\) 是非线性的,但对于 \(\theta\) 仍保持线性,因为非线性参数被蕴含到特征向量中。这将有助于后续的求解 \(\theta\) 的过程。
值函数近似
值函数近似的核心思想是用参数化函数替代表格形式的值函数,从而将强化学习的问题转化为一个优化问题。我们用带有参数的函数 \(\hat{q}(s, a; \theta)\) 或 \(\hat{v}(s; \theta)\) 近似动作价值函数 \(q(s, a)\) 或状态价值函数 \(v(s)\),其中 \(\theta\) 是函数的参数集合(例如神经网络的权重)。
目标函数定义
值函数近似需要定义一个目标函数来衡量当前近似值函数与真实值函数的偏差。最常用的目标函数是均方误差(Mean Squared Error,MSE)形式: \[ J(\theta) = \mathbb{E}\left[\left( v_\pi(S) - \hat{v}(S; \theta) \right)^2 \right], \] 通过最小化 \(J(\theta)\),我们可以找到最优参数 \(\theta^*\)。注意,这里的均值 \(\mathbb{E}\) 有两种处理方法:
- 平均分布(Uniform Distribution):平等看待所有状态,乘以 \(1/|\mathcal{S}|\)。但这样并不好,因为目标状态和接近目标的状态实际上会更重要!
- 稳态分布(Stationary Distribution):用于描述长期行为(long-run behavior),将一个智能体长期放置在环境中,以策略 \(\pi\) 进行交互,最终可以统计出智能体在每个状态停留的概率 \(\{d_\pi(s)\}_{s\in \mathcal{S}}\)。
稳态分布也被称为 Steady-state Distribution 或 Limiting Distribution,在这一分布下,目标函数可以转化为: \[ J(\theta) = \mathbb{E}\left[\left( v_\pi(S) - \hat{v}(S; \theta) \right)^2 \right]=\sum_{s \in \mathcal{S}} d_\pi(s)\left(v_\pi(s)-\hat{v}(s; \theta)\right)^2 \] 在有模型的情况下,\(d_\pi(s)\) 也可以直接用迭代法计算出来: \[ d_\pi^\top=d_\pi^\top P_\pi \]
优化算法和函数选择
值函数近似中,参数优化的核心方法包括梯度下降(Gradient Descent)及其变种算法。针对目标函数 \(J(\theta)\),通过对 \(\theta\) 计算梯度,可以更新参数:
\[ \theta_{t+1} = \theta_t - \alpha \nabla_\theta J(\theta_t), \]
其中梯度可以展开为: \[ \begin{aligned} \nabla_\theta J(\theta) & =\nabla_\theta \mathbb{E}\left[\left(v_\pi(S)-\hat{v}(S; \theta)\right)^2\right] \\ & =\mathbb{E}\left[\nabla_\theta\left(v_\pi(S)-\hat{v}(S; \theta)\right)^2\right] \\ & =2 \mathbb{E}\left[\left(v_\pi(S)-\hat{v}(S; \theta)\right)\left(-\nabla_\theta \hat{v}(S; \theta)\right)\right] \\ & =-2 \mathbb{E}\left[\left(v_\pi(S)-\hat{v}(S; \theta)\right) \nabla_\theta \hat{v}(S; \theta)\right] \end{aligned} \] 为了消除求期望运算,我们使用随机梯度下降,则更新公式变为: \[ \theta_{t+1} = \theta_t + \alpha_t \left(v_\pi(s_t)-\hat{v}(s_t; \theta_t)\right) \nabla_\theta \hat{v}(s_t; \theta_t) \] 但还有一个问题,\(v_\pi(s_t)\) 是未知的。这里有两种方法:
基于 MC Learning 的方法,使用采样的累计汇报 \(g_t\) 来代替: \[ \theta_{t+1} = \theta_t + \alpha_t \left(g_t-\hat{v}(s_t; \theta_t)\right) \nabla_\theta \hat{v}(s_t; \theta_t) \]
基于 TD Learning 的方法,使用 TD Target 来代替: \[ \theta_{t+1} = \theta_t + \alpha_t \left(r_{t+1} + \gamma \hat{v}(s_{t+1};\theta_t) -\hat{v}(s_t; \theta_t)\right) \nabla_\theta \hat{v}(s_t; \theta_t) \]
函数选择方面,我们可以使用以下模型进行值函数的近似:
线性模型:线性函数 \(\hat{v}(s; \theta) = \phi(s)^\top \theta\),其中 \(\phi(s)\) 是状态特征向量,需要人工选取特征。此时优化算法也称为 TD-Linear: \[ \theta_{t+1} = \theta_t + \alpha_t \left(r_{t+1} + \gamma \phi^\top(s_{t+1}) \theta_t -\phi^\top(s_{t}) \theta_t\right) \phi(s_t) \]
非线性模型:如多层感知机(MLP)或卷积神经网络(CNN),无需人工选取特征,适用于处理高维状态空间和复杂特征,但缺乏可解释性。
核方法:如高斯核函数,能够较为自然地处理非线性映射。
TD 优化目标分析
前面介绍到最常用的目标函数是均方误差形式的真实残差(True Value Error): \[ J_E(\theta) = \mathbb{E}\left[\left( v_\pi(S) - \hat{v}(S; \theta) \right)^2 \right]=\left\| v_\pi - \hat{v}(\theta) \right\|^2_D \] 其中 \(\left\| \cdot \right\|\) 表示向量取模,下角标 \(D\) 表示 \(\{d_\pi(s)\}_{s\in \mathcal{S}}\) 构成的对角矩阵,一般有 \(\left\| X \right\|^2_D=X^\top D X\)。
实际上,还有另一种贝尔曼残差(Bellman Error)写为: \[ J_{BE}(\theta)=\left\|\hat{v}(\theta)-\left(r_\pi+\gamma P_\pi \hat{v}(\theta)\right)\right\|_D^2 \doteq\left\|\hat{v}(\theta)-T_\pi(\hat{v}(\theta))\right\|_D^2 \] 其中 \(T_\pi(x) \doteq r_\pi+\gamma P_\pi x\),这是因为我们希望拟合的值函数也满足贝尔曼公式,但实际上这两个值可能不相等,于是我们就去最小化贝尔曼残差。
而当我们用 TD Target 代替 \(v_\pi(s_t)\) 时,还要考虑到函数选择的问题。由于我们选择的函数很可能最终无法完全逼近真实值函数(例如线性模型),因此 \(\hat{v}(\theta)\) 和 \(T_\pi(\hat{v}(\theta))\) 可能永远也不会相等,此时我们会对 \(T(x)\) 再进行一次投影,使其最终能够等于零: \[ J_{PBE}(\theta)=\left\|\hat{v}(\theta)-MT_\pi(\hat{v}(\theta))\right\|_D^2 \] 此时的目标我们称为投影贝尔曼残差(Projected Bellman Error)。
案例分析
下面用一个网格世界的案例来分析值函数近似的效果,我们首先给出最优状态值对应的可视化结果:
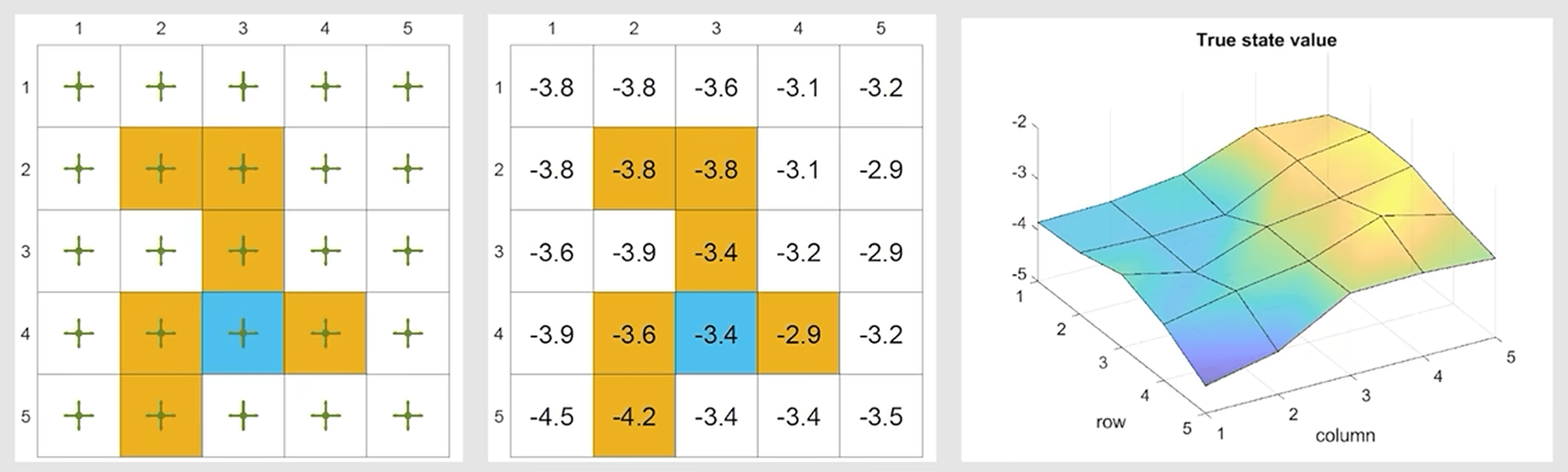
我们可以利用经验数据进行迭代估计,如果使用 Tabular 方法,则最终结果如下:
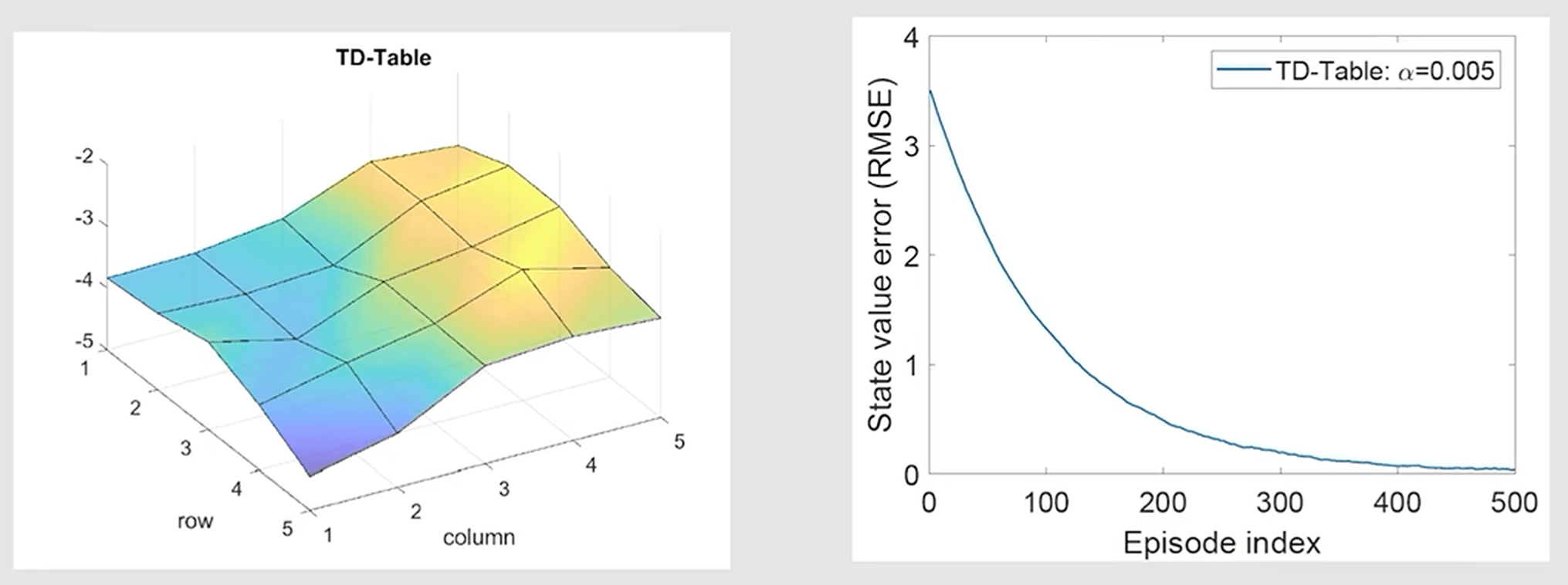
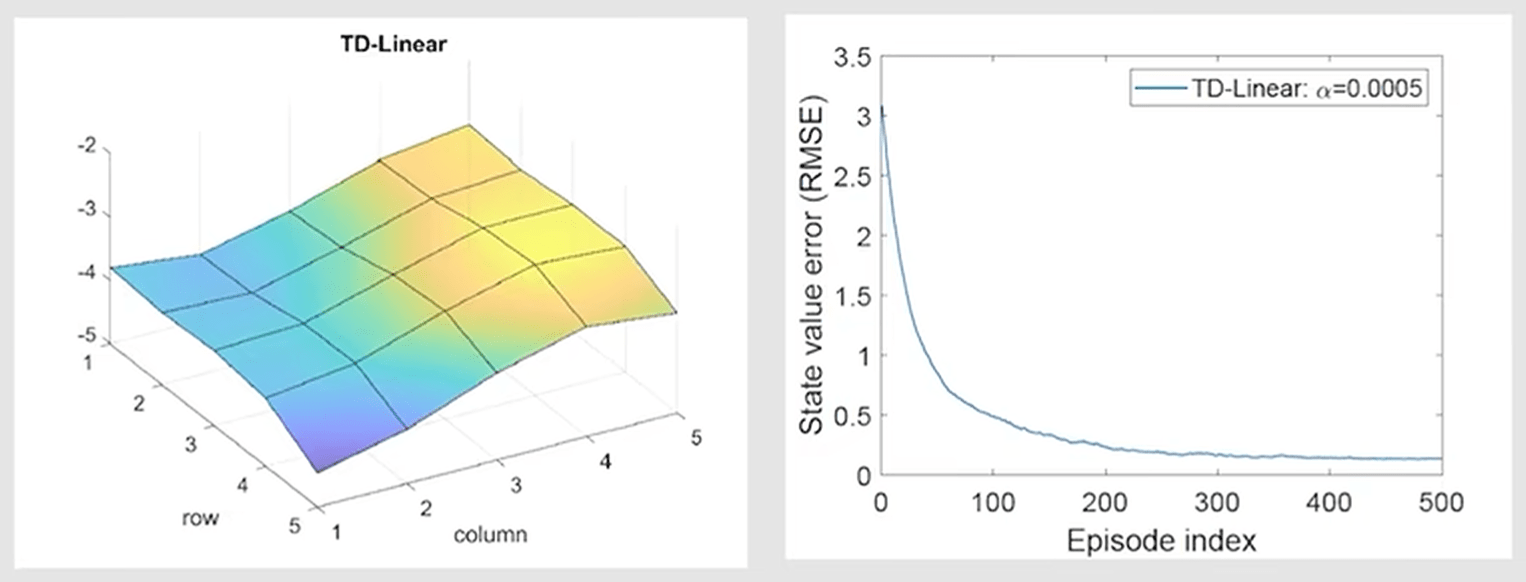
可以看到随着使用的经验数据变多,均方误差接近 \(0\),可视化效果也十分接近真实值。而如果使用一阶线性模型近似,则最终结果如下:
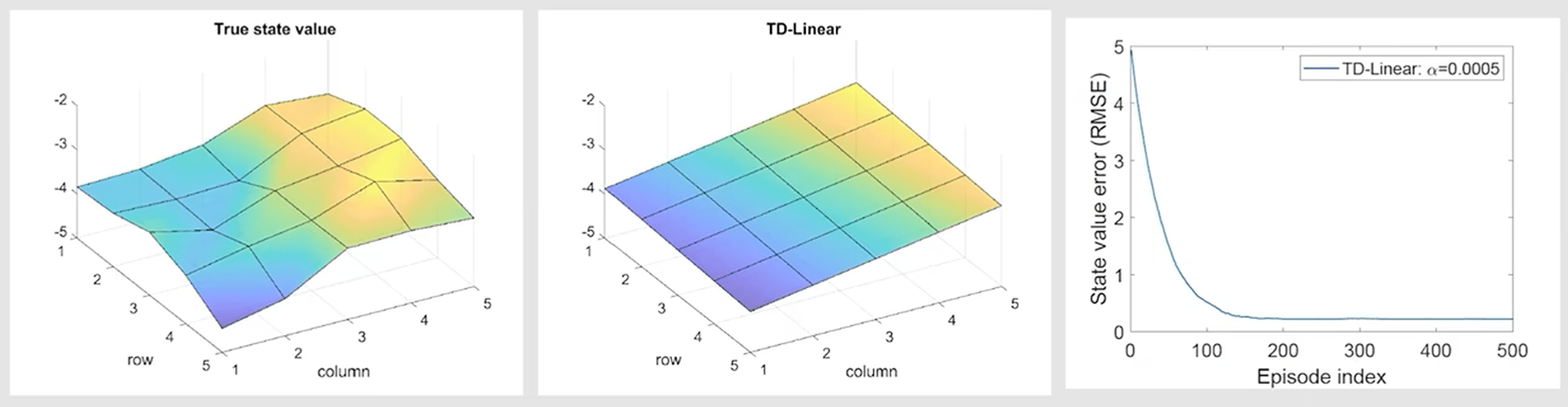
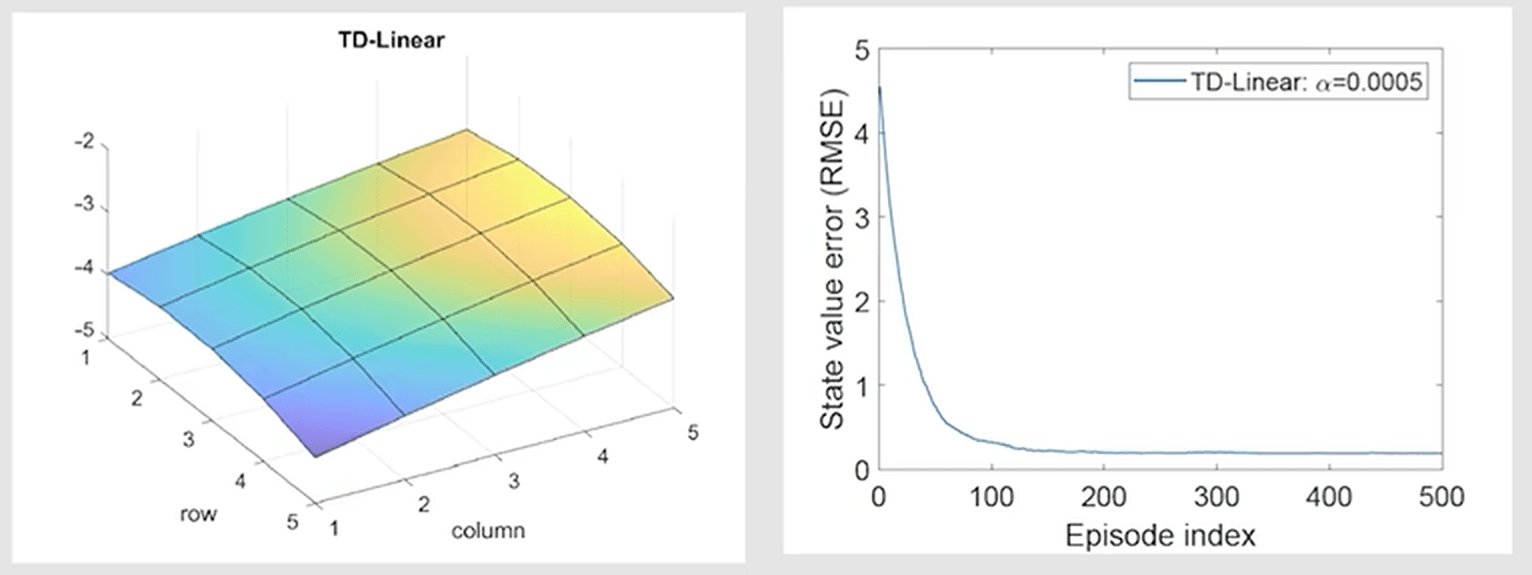
可以看到拟合出的趋势接近,但实际值仍有较大误差。如果使用更高阶的模型,则效果将会更加还原:
SARSA 和 Q-Learning 的应用
前面的介绍都是以状态值为主,但我们知道在实际应用中,动作价值将更有助于找到最优策略。这里我们将值函数近似与 SARSA 和 Q-Learning 算法结合,实现对高维状态空间的高效学习。
近似 SARSA:使用 \(\hat{q}(s, a; \theta)\) 替代表格形式的 \(q(s, a)\),更新公式为: \[ \theta_{t+1} = \theta_t + \alpha_t \left( r_{t+1} + \gamma \hat{q}(s_{t+1}, a_{t+1}; \theta_t) - \hat{q}(s_t, a_t; \theta_t) \right) \nabla_\theta \hat{q}(s_t, a_t; \theta_t). \]
近似 Q-Learning:更新公式为: \[ \theta_{t+1} = \theta_t + \alpha_t \left( r_{t+1} + \gamma \max_{a \in A(s_{t+1})} \hat{q}(s_{t+1}, a; \theta_t) - \hat{q}(s_t, a_t; \theta_t) \right) \nabla_\theta \hat{q}(s_t, a_t; \theta_t). \]
与 Tabular 形式的 SARSA 和 Q-Learning 区别在于,我们现在不直接更新 \(q_t(s,a)\),而是更新模型参数 \(\theta_t\)。
在迭代收敛后,也就完成了策略评估(PE),之后的策略改进(PI)也和之前类似,只不过在选择最优动作时 \(a=\arg \max_{a \in A(s_t)} \hat{q}(s_t, a; \theta_t)\) 不能直接索引,而是要代入 \(\hat{q}\) 算出函数值再比较。
Deep Q-Network | DQN
值函数近似的进一步发展是深度 Q 网络(Deep Q-Network,DQN),它将深度学习引入到 Q-Learning 中,使用深度神经网络近似动作价值函数,也被称为 Deep Q-Learning。
DQN 的更新公式与近似 Q-Learning 完全一致,只不过 \(\hat{q}(s, a; \theta)\) 使用了深度神经网络:
\[ \theta_{t+1} = \theta_t + \alpha_t \left( r_{t+1} + \gamma \max_{a \in A(s_{t+1})} \hat{q}(s_{t+1}, a; \theta_t) - \hat{q}(s_t, a_t; \theta_t) \right) \nabla_\theta \hat{q}(s_t, a_t; \theta_t). \]
其优化目标自然就是贝尔曼最优残差(Bellman Optimality Error): \[ J_{BOE}(\theta)=\mathbb{E}\left[\left( R+\gamma \max_{a \in A(S')} \hat{q}(S', a; \theta) - \hat{q}(S,A;\theta) \right)^2 \right] \]
目标网络 | Target Network
有了这个目标后,我们自然想到用梯度下降来求解。对于 \(\hat{q}(S,A;\theta)\) 很容易就能求出其梯度,但对于 \(\max \hat{q}(S', a; \theta)\) 则必须用上特殊的技巧。
在 DQN 中,我们令: \[ y \doteq R+\gamma \max_{a \in A(S')} \hat{q}(S', a; \theta) \] 在优化过程中,通过将 \(y\) 固定为一个常量,就可以免去 \(\max\) 项的优化。具体而言,我们引入两个网络:
- 主网络(Main network):\(\hat{q}(s,a;\theta)\),持续优化的主网络参数,每一步需要计算 \(\nabla \hat{q}(s,a;\theta)\) 进行梯度下降;
- 目标网络(Target network):\(\hat{q}(s,a;\theta_T)\),是主网络参数的一个延迟副本,在优化的时候每隔固定步数将主网络参数复制到目标网络中,而非每一步都更新。
这样一来,我们就避免了复杂的求梯度运算,且可以让目标值变得更加稳定、单一,从而避免训练过程中振荡或发散。
经验回放 | Experience Replay
DQN 还引入了经验回放(Experience Replay)机制,用来打破数据之间的时序相关性并提高样本效率。经验回放的主要步骤如下:
- 存储经验:将每一步 \((s_t, a_t, r_{t+1}, s_{t+1})\) 存入回放缓冲区(Replay Buffer)。
- 随机采样:从缓冲区中随机抽取一个小批量(mini-batch)的经验样本。这种采样方式可以去除经验之间的时序相关性,近似独立同分布(i.i.d.)。
- 训练网络:基于抽取的样本计算损失函数,并更新网络参数。
那么,接下来有几个问题还需要回答:为什么经验回放对于 DQN 来说是必须的?为什么采样必须服从均匀分布(Uniform Distribution),即每个样本采样概率相等?
在目标函数 \(J_{BOE}(\theta)\) 中,我们假设 \((S,A)\sim d\),其中 \(d\) 是一个分布,\((S,A)\) 整体视作一个随机变量。在没有明确的先验知识时,通常假设 \(d\) 是均匀分布,即所有状态-动作对同等重要。
但在采集数据时,智能体是按照时序顺序生成数据的,导致样本实际分布可能偏离均匀分布。因此,均匀随机采样是一个有效的近似手段,能够尽可能还原目标函数的分布假设。
第二个问题,经验回放是如何提高样本效率的?为什么现在需要样本效率了?
- Replay Buffer 中的经验允许被反复采样,多次利用。此外,某些关键状态(例如稀疏奖励问题中接近奖励的状态)可能在直接采样的过程中较少出现,经验回放通过保留这些状态,确保训练时样本的多样性。甚至我们可以使用优先经验回放(Prioritized Experience Replay),经验的优先级根据其 TD Error 动态更新,确保关键状态的学习次数。
- 深度神经网络通常需要大量的数据来稳定训练。如果只依赖实时采样生成的数据,可能无法充分训练神经网络。
第三个问题,为什么之前表格形式的 Q-Learning 不需要经验回放?
- Deep Q-Learning 的目标是最小化一个标量目标函数 \(\mathbb{E}_{*,S,A}\),因此必然涉及到 \((S,A)\) 的分布,也就需要假设均匀分布,进而需要随机采样。
- 而基于表格的 Q-Learning 的目标是求解贝尔曼最优公式 —— 对于每个 \((s,a)\) 都要满足的公式,因此不会涉及到分布问题。当然,由于 Q-Learning 本身是 off-policy 的,因此想用经验回放也完全没问题!
具体步骤
以下是 DQN 的具体步骤:
初始化主网络参数 \(\theta\) 和目标网络参数 \(\theta_{T} = \theta\)。
初始化回放缓冲区 \(\mathcal{B}=\{\}\)。
重复以下步骤(直到训练完成):
与环境交互(On-Policy / Off-Policy 都行),得到经验元组 \((s_t, a_t, r_{t+1}, s_{t+1})\) 并存入缓冲区;
从缓冲区 \(\mathcal{B}\) 随机采样一个小批量经验;
计算目标值(通过目标网络参数): \[ y_T = r_{t+1} + \gamma \max_{a'} \hat{q}(s_{t+1}, a'; \theta_T) \]
最小化损失函数: \[ J(\theta) = \mathbb{E} \left[ \left( y_T - \hat{q}(s_t, a_t; \theta) \right)^2 \right] \]
用梯度下降(反向传播)更新主网络参数 \(\theta\);
每隔固定步数 \(C\) 将主网络参数复制到目标网络参数 \(\theta_T\)。
策略更新:
- 如果是 On-Policy,需要在更新完 \(\theta\) 根据 \(\hat{q}\) 后更新 \(\hat{\pi}\),再用于和环境交互生成经验;
- 如果是 Off-Policy,则只需要在训练完成后,用收敛的 \(\hat{q}\) 计算出最终 \(\hat{\pi}\) 即可。