PR学习笔记 #4 概率密度:非参数估计
本文最后更新于:2022年5月19日 中午
上一节介绍了概率密度的 参数估计 方法,并以最常见的正态分布为例推导了计算公式。然而,并不是所有的分布都可以提前假设的。
当我们观测样本后,发现其概率密度分布的形式不典型时,就需要用到非参数估计方法。
非参数估计 | Nonparametric Estimation
非参数估计就是在概率密度形式未知,根据样本点 \(X_1,X_2,\cdots,X_n\) 直接推断出概率密度函数本身的过程。
回顾前文的贝叶斯分类,我们知道如果属性 \(A_k\) 是离散的,可以直接用 \(a_k\) 在类别中的比例估计之。这时,我们通常需要大量的样本与监督学习。
这种思想也可以延申到连续属性的 Histogram Algorithm (直方图算法):将连续的浮点特征值离散化为 \(K\) 个整数,将特征值的取值范围分割为 \(K\) 个区间。遍历数据,根据浮点值落在区间的样本数在直方图中累计统计量。
这种方法在 LightGBM 中得到应用,使得内存占用更小(只保存离散化后的值)和计算代价更小(决策树分裂的代价)。
而在非参数估计中,我们也是基于统计的思想——若在概率密度函数 \(p(x)\) 中固定区间 \(R\),则随机变量 \(x\) 落入区间 \(R\) 的概率为: \[ P=\int_R{p\left( x \right) \mathrm{d}x} \] 当区间 \(R\) 足够小时,我们可以认为 \(p(x)\) 在区间内保持不变,记区间体积为 \(V\),上式转化为: \[ P=\int_R{p\left( x \right) \mathrm{d}x}=p(x)V \] 当然,上述概率是在已知 \(p(x)\) 的情况下求得。对于总样本数为 \(N\) 的数据集中,我们可以用落在区间中的样本数 \(k\) 来近似估计: \[ \hat{P}\approx \frac{k}{N} \] 从而我们可以得到 \(p(x)\) 的近似估计: \[ \hat{p}\left( x \right) \approx \frac{k/V}{N} \]
当样本数量趋于无限时,\(\hat{p}\left( x \right)\) 依概率收敛于 \(p(x)\),当且仅当满足下列条件: \[ \underset{N\rightarrow \infty}{\lim}V_N=0 ,\quad \underset{N\rightarrow \infty}{\lim}k_N=\infty ,\quad \underset{N\rightarrow \infty}{\lim}\frac{k_N}{N}=0 \]
下面介绍的两种方法,是非参数估计的具体实现,分别依赖于估计式中 \(V\) 和 \(k\)。
Parzen 窗法
Parzen 窗法的核心是:\(V\) 不变,\(k\) 可变。通过选取固定大小的「窗」,使其遍布整个空间,并估算每个窗的 $( x ) $ 作为窗中心的概率密度。
假设 \(d\) 维空间中的样本点为 \(x=\left[u_{1}, u_{2}, \ldots, u_{d}\right]^{T}\) ,且空间中每个小窗是一个超立方体,它在每一维的棱长都为 \(h\),则小窗的体积是: \[ V=h^d \] 要计算每个小窗内落入的样本数目,可以定义如下的 \(d\) 维单位方窗函数: \[ \varphi\left(\left[u_{1}, u_{2}, \ldots, u_{d}\right]^{T}\right)=\left\{\begin{array}{lc} 1 & \text { 若 }\left|u_{j}\right| \leqslant \frac{1}{2}, j=1,2, \cdots, d \\ 0 & \text { 其他 } \end{array}\right. \] 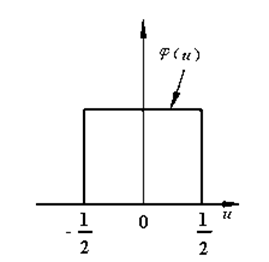
该函数在以原点为中心的 \(d\) 维单位超立方体内取值为 1,在其他地方取值为 0。对于每个样本点 \(x_i\),我们只需计算 $( ) $ 就可以知道其是否落在观测点 \(x\) 为中心、\(h\) 为棱长的方窗内。现在共有 \(N\) 个样本点,那么就有: \[ k_{N}=\sum_{i=1}^{N} \varphi\left(\frac{x-x_{i}}{h}\right) \] 将上式代入 \(\hat{p}\left( x \right) \approx \frac{k/V}{N}\) 中有: \[ \hat{p}\left( x \right) \approx \frac{1}{N V} \sum_{i=1}^{N} \varphi\left(\frac{x-x_{i}}{h}\right) \] 或者,我们将 \(V\) 放入求和号中,并定义非单位的方窗函数(核函数)如下: \[ K\left(x, x_{i}\right)=\frac{1}{V} \varphi\left(\frac{x-x_{i}}{h}\right) \] 核函数反映了在方窗情形下,任意一个样本点 \(x_i\) 对于观测点 \(x\) 处的概率密度的「贡献」。而我们要计算的的概率密度函数,就可以看作是所有样本点对观测点的贡献进行平均: \[ \hat{p}\left( x \right) \approx \frac{1}{N} \sum_{i=1}^{N}K\left(x, x_{i}\right) \]
核函数的选取
超立方体的棱角带来了一些数据处理上的不合理,如果改用超球体,则可以得到超球窗函数: \[ K\left(x, x_{i}\right)=\left\{\begin{array}{cc} V^{-1} & \text { 若 }|| x-x_{i} \| \leqslant \rho \\ 0 & \text { 其他 } \end{array}\right. \] 其中,距离的度量采用了范数,$$ 为超球体的半径。仅当样本点落在超球体内时,其对概率密度有贡献。
然而,方窗和超球窗都有一个不足之处:忽略了距离这一特征。所有落在区域内的样本点一视同仁,而其他点则都被忽视,这就导致了 \(h\) 和 \(\rho\) 的取值对结果的影响很大。宽度过大会使得分辨率变低,而宽度过小则不平滑效应明显。
因此,我们考虑用连续函数计算贡献,只需要满足以下两点:
- 任意点处贡献不为负:\(K\left(x, x_{i}\right)\geqslant 0\)
- 任一样本点对整个空间的总贡献之和为 1:\(\int K\left(x, x_{i}\right)\mathrm{d}x=1\)
这样可以确保最终估算出的 \(\hat{p}\left( x \right)\) 的总和也为 1。由此,我们引入正态窗函数(高斯窗函数): \[ K\left(x, x_{i}\right)=\frac{1}{\sqrt{(2 \pi)^{d} \rho^{2 d}|Q|}} \exp \left\{-\frac{1}{2} \frac{\left(x-x_{i}\right)^{T} Q^{-1}\left(x-x_{i}\right)}{\rho^{2}}\right\} \] 即以样本 \(x_i\) 为均值、协方差矩阵为 \(\Sigma=\rho^{2} Q\) 的高维正态分布函数。
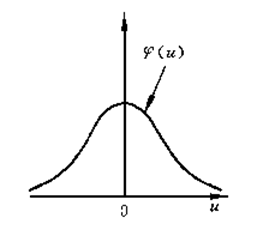
同理,还有指数窗函数: \[ K\left(x, x_{i}\right)=\exp \left\{-\frac{1}{2} || x-x_{i} \|\right\} \] 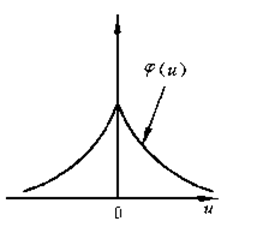
KNN 法
K 近邻法的核心是:\(k\) 不变,\(V\) 可变。固定每一个「窗」中落入的样本数,而窗本身的体积可变化,并估算每个窗的 $( x ) $ 作为窗中心的概率密度。
假设 \(d\) 维空间中的样本点为 \(x=\left[u_{1}, u_{2}, \ldots, u_{d}\right]^{T}\) ,具体的做法是先选定一个 \(k_N\),再在点 \(x\) 的周围,不断扩大窗的体积,直到捕捉到 \(k_N\) 个样本为止。
通常取 \(k_N=\sqrt{N}\),窗的形状选择超球窗,半径为第 \(k_N\) 个近邻点到样本点的距离。